

Index : Hands On System Design with "Distributed Systems Implementation - 254-Lesson’s curriculum"
Upgrade to Lifetime Access subscription & Get one year free subscription to Hands on course portal : “systemdrd.com” that offers wide variety of hands on courses on covering multiple high demanding technologies
The Definitive 254-Lesson Roadmap to Distributed Systems Mastery.
Most engineers know the theory, but few can implement a truly resilient distributed system from scratch. This curriculum bridges that gap. Over 254 hands-on lessons, we move past the whiteboard to build the “nervous system” of modern software. This is a rigorous, code-heavy implementation guide designed for those who want to master the complexities of scalability, fault tolerance, and high-concurrency architecture. Subscribe now
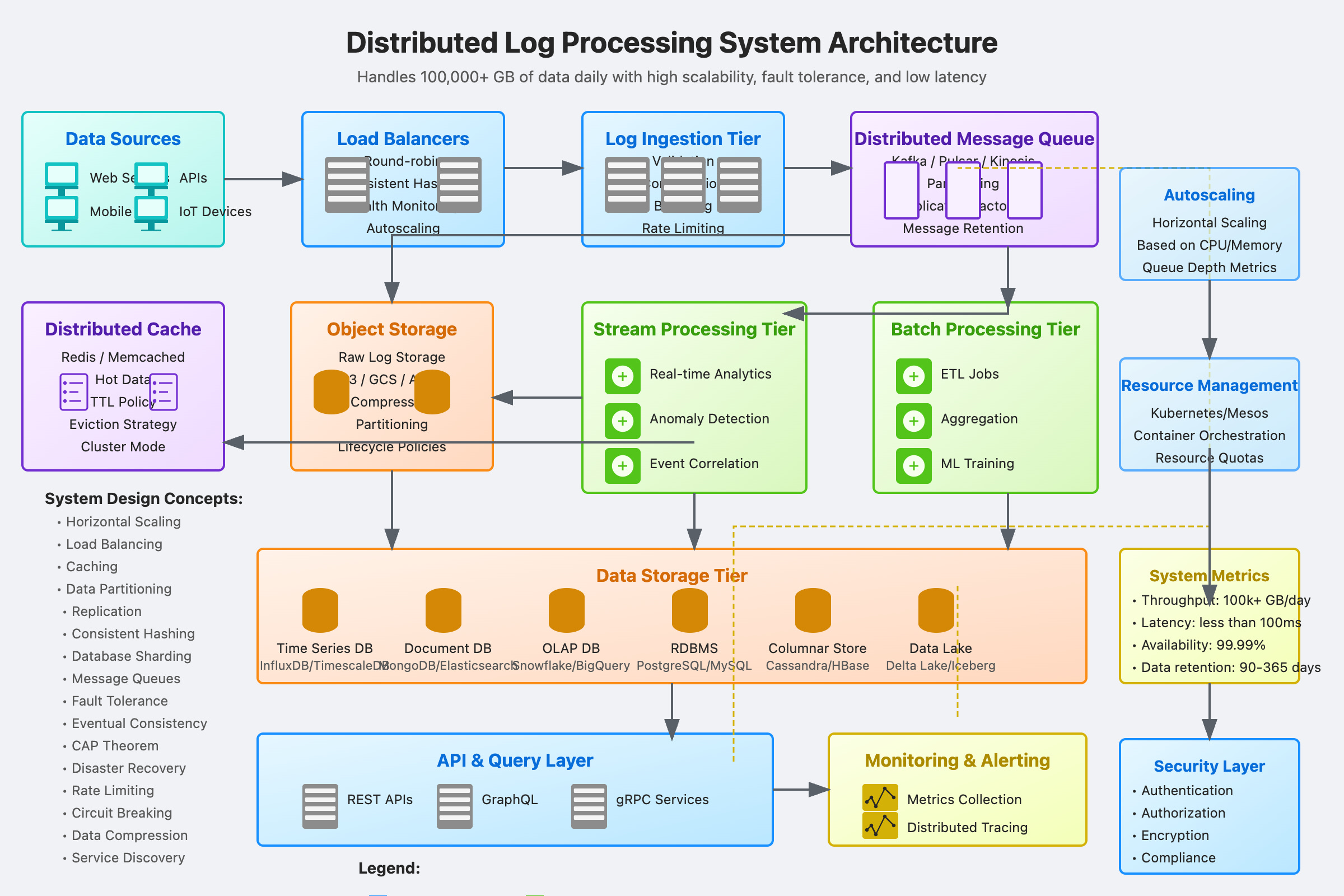
254-Lesson’s Distributed Log Processing System Implementation
This curriculum guides you through building a complete distributed log processing system from scratch. Each day features practical, hands-on tasks with concrete outputs, assuming you already have programming and CS fundamentals.
Try out first 3 lessons free exclusively for you to see usefulness of this course take a look.
Module 1: Foundations of Log Processing (Days 1-30)
Week 1: Setting Up the Infrastructure
Day 1: Set up development environment (Docker, Git, VS Code) and create project repository
Output: Configured development environment with all necessary tools and initialized repository
Day 2: Implement a basic log generator that produces sample logs at configurable rates
Output: Working log generator that creates timestamped events with configurable throughput
Day 3: Create a simple log collector service that reads local log files
Output: Service that watches log files and detects new entries
Day 4: Implement log parsing functionality to extract structured data from common log formats
Output: Parser for Apache/Nginx logs that extracts timestamp, IP, status code, etc.
Day 5: Build a basic log storage mechanism using flat files with rotation policies
Output: Log storage system with configurable rotation based on size/time
Day 6: Create a simple CLI tool to query and filter collected logs
Output: Command-line utility that can search and filter logs using basic patterns
Day 7: Integrate the components into a simple local log processing pipeline
Output: End-to-end system generating, collecting, storing, and querying logs on a single machine
Week 2: Network-Based Log Collection
Day 8: Implement a TCP server to receive logs over the network
Output: Server accepting TCP connections with log data
Day 9: Create a log shipping client that forwards logs to the TCP server
Output: Client sending logs from one machine to another over TCP
Day 10: Add UDP support for high-throughput log shipping
Output: Server and client handling log transmission over UDP
Day 11: Implement batching in the log shipper to optimize network usage
Output: Client that efficiently batches logs with configurable batch size and interval
Day 12: Add compression to reduce network bandwidth usage
Output: Compressed log transmission with measurable bandwidth reduction
Day 13: Implement TLS encryption for secure log transmission
Output: Encrypted log transmission with certificate management
Day 14: Build a simple load generator and measure throughput of the system
Output: Benchmark report showing logs/second processing capability
Week 3: Data Serialization and Formats
Day 15: Add JSON support for structured log data
Output: End-to-end JSON log processing with schema validation
Day 16: Implement Protocol Buffers for efficient binary serialization
Output: Log system using Protocol Buffers with measurable performance gain
Day 17: Create Avro serialization support for schema evolution
Output: Log system using Avro with schema versioning demonstration
Day 18: Implement log normalization to convert between formats
Output: Service that can transform logs between different formats (text, JSON, Protobuf, Avro)
Day 19: Add a schema registry service for format management
Output: Central service for managing and validating log formats and schemas
Day 20: Build compatibility layer for common logging formats (syslog, journald)
Output: Adapters for ingesting logs from system services
Day 21: Implement a simple log enrichment pipeline adding metadata to raw logs
Output: Service that augments logs with additional context (hostname, environment, etc.)
Week 4: Distributed Log Storage
Day 22: Set up a multi-node storage cluster using simple file replication
Output: Log storage distributed across multiple nodes with basic replication
Day 23: Implement partitioning strategy for logs based on source or time
Output: Partitioned storage demonstrating improved query performance
Day 24: Add consistent hashing for balanced distribution
Output: Storage nodes with even distribution of logs using consistent hashing
Day 25: Implement leader election for cluster management
Output: Storage cluster with automatic leader election recovery
Day 26: Create a cluster membership and health checking system
Output: Self-healing cluster that detects and handles node failures
Day 27: Build a distributed log query system across partitions
Output: Query tool that can retrieve logs from across the cluster
Day 28: Implement read/write quorums for consistency control
Output: Configurable consistency levels with demonstration of tradeoffs
Day 29: Add anti-entropy mechanisms to repair inconsistencies
Output: Background process that detects and fixes replication inconsistencies
Day 30: Measure and optimize cluster performance
Output: Performance report with throughput and latency metrics
Module 2: Scalable Log Processing (Days 31-60)
Week 5: Message Queues for Log Processing
Day 31: Set up a RabbitMQ instance for log message distribution
Output: Working message queue for log distribution
Day 32: Create producers to send logs to message queues
Output: Log collector publishing to message queues
Day 33: Implement consumers to process logs from queues
Output: Workers consuming and processing logs from queues
Day 34: Add consumer acknowledgments and redelivery mechanisms
Output: Reliable message processing with failure handling
Day 35: Implement different exchange types for routing patterns
Output: Topic-based routing of logs to different processing pipelines
Day 36: Add dead letter queues for handling failed processing
Output: System capturing and managing failed log processing attempts
Day 37: Implement priority queues for critical log messages
Output: Demonstration of high-priority logs bypassing normal processing queues
Week 6: Stream Processing with Kafka
Day 38: Set up a Kafka cluster for log streaming
Output: Working Kafka cluster for high-throughput log streaming
Day 39: Create Kafka producers for log ingestion
Output: Log shippers sending data to Kafka topics
Day 40: Implement Kafka consumers for log processing
Output: Consumers reading and processing logs from Kafka
Day 41: Set up partitioning and consumer groups
Output: Parallel processing across multiple consumer instances
Day 42: Add exactly-once processing semantics
Output: System guaranteeing no duplicate log processing
Day 43: Implement log compaction for state management
Output: Compacted topics maintaining latest state of entities
Day 44: Create a real-time monitoring dashboard using Kafka Streams
Output: Dashboard showing live statistics of log processing
Week 7: Distributed Log Analytics
Day 45: Implement a simple MapReduce framework for batch log analysis
Output: System performing word count and pattern frequency analysis
Day 46: Add time-based windowing for aggregation
Output: Analytics calculating statistics over time windows
Day 47: Implement sliding windows for moving averages
Output: Real-time trend analysis with sliding windows
Day 48: Add sessionization for tracking user activity
Output: Session analysis identifying user behavior patterns
Day 49: Implement anomaly detection algorithms
Output: System detecting unusual patterns in logs
Day 50: Create alert generation based on log patterns
Output: Alerting system triggered by specific log conditions
Day 51: Build dashboards for visualizing analytics results
Output: Web interface displaying key metrics and trends
Week 8: Distributed Log Search
Day 52: Implement a simple inverted index for log searching
Output: Search index enabling quick text searches across logs
Day 53: Add distributed indexing across multiple nodes
Output: Partitioned search index spanning multiple machines
Day 54: Implement a query language for complex searches
Output: Parser and executor for SQL-like queries on logs
Day 55: Add faceted search capabilities
Output: Search system with filtering by multiple dimensions
Day 56: Implement real-time indexing of incoming logs
Output: Search system with minimal indexing latency
Day 57: Add full-text search capabilities with ranking
Output: Search system with relevance scoring
Day 58: Build a search API for programmatic access
Output: RESTful API for querying log data
Week 9: High Availability and Fault Tolerance
Day 59: Implement active-passive failover for critical components
Output: Automatic failover demonstration with minimal downtime
Day 60: Create multi-region replication for log data
Output: Log replication across simulated regions
Module 3: Advanced Log Processing Features (Days 61-90)
Week 9 (continued): High Availability and Fault Tolerance
Day 61: Add circuit breakers for handling component failures
Output: System maintaining availability when components fail
Day 62: Implement backpressure mechanisms for load management
Output: System gracefully handling traffic spikes
Day 63: Create chaos testing tools to simulate failures
Output: Test suite that randomly introduces failures to verify resilience
Week 10: Security and Compliance
Day 64: Implement role-based access control for log data
Output: Authentication and authorization system for log access
Day 65: Add field-level encryption for sensitive log data
Output: Encryption system protecting PII in logs
Day 66: Implement log redaction for compliance
Output: System automatically redacting sensitive information
Day 67: Create audit trails for log access
Output: Immutable record of who accessed what log data
Day 68: Implement data retention policies
Output: Automated system for enforcing retention periods
Day 69: Add GDPR compliance features (right to be forgotten)
Output: System capable of selectively removing specific user data
Day 70: Create compliance reports and export capabilities
Output: Automated report generation for compliance audits
Week 11: Performance Optimization
Day 71: Profile and optimize log ingestion pipeline
Output: Performance improvements with before/after metrics
Day 72: Implement adaptive batching based on system load
Output: Self-tuning batch sizes maximizing throughput
Day 73: Add caching layers for frequent queries
Output: Query response time improvements with caching
Day 74: Optimize storage format for read/write patterns
Output: Storage format optimized for specific workloads
Day 75: Implement bloom filters for efficient existence checking
Output: Faster membership queries with bloom filters
Day 76: Add delta encoding for log storage efficiency
Output: Reduced storage requirements with delta compression
Day 77: Implement adaptive resource allocation
Output: System that scales resources based on demand
Week 12: Advanced Analytics
Day 78: Build a machine learning pipeline for log classification
Output: ML model classifying logs by severity/category
Day 79: Implement clustering for pattern discovery
Output: System identifying common patterns in logs
Day 80: Add predictive analytics for forecasting
Output: Predictions of system behavior based on log patterns
Day 81: Implement a recommendation system for troubleshooting
Output: System suggesting fixes based on similar past incidents
Day 82: Create correlation analysis across different log sources
Output: System identifying relationships between events in different logs
Day 83: Build a root cause analysis engine
Output: System tracing issues to their origin based on logs
Day 84: Implement natural language processing for log understanding
Output: System extracting meaning from free-text log messages
Module 4: Building a Complete Distributed Log Platform (Days 91-120)
Week 13: API and Service Layer
Day 85: Design and implement a RESTful API for the log platform
Output: Complete API documentation and implementation
Day 86: Add GraphQL support for flexible queries
Output: GraphQL endpoint for complex log queries
Day 87: Implement rate limiting and quota management
Output: Protection against API abuse with configurable limits
Day 88: Create SDK libraries for common languages
Output: Client libraries for Java, Python, and JavaScript
Day 89: Build a CLI tool for platform interaction
Output: Command-line client for log system management
Day 90: Implement webhook notifications for log events
Output: Notification system pushing events to external systems
Day 91: Add batch API operations for efficiency
Output: API endpoints supporting bulk operations
Week 14: Web Interface and Dashboards
Day 92: Create a basic web UI for log viewing
Output: Web interface for browsing logs
Day 93: Implement real-time log streaming to the UI
Output: Live log tail feature in the web interface
Day 94: Add advanced search interface with filters
Output: Rich search UI with multiple filtering options
Day 95: Create customizable dashboards
Output: User-configurable dashboards for monitoring
Day 96: Implement data visualization components
Output: Charts and graphs showing log patterns and trends
Day 97: Add saved searches and alerts in the UI
Output: Feature for saving searches and configuring alerts
Day 98: Implement user preferences and settings
Output: Personalized user experience with saved preferences
Week 15: Advanced Operational Features
Day 99: Create a health monitoring system for the platform
Output: Internal monitoring tracking all component health
Day 100: Implement automated scaling policies
Output: Self-scaling system adjusting to load changes
Day 101: Add blue/green deployment capabilities
Output: Zero-downtime upgrade process
Day 102: Implement A/B testing framework for features
Output: System for gradually rolling out new features
Day 103: Create comprehensive metrics collection
Output: Detailed performance metrics for all components
Day 104: Build cost allocation and usage reporting
Output: Reports showing resource usage by tenant/user
Day 105: Implement automated backup and recovery
Output: Scheduled backups with verified restore capability
Week 16: Multi-tenancy and Enterprise Features
Day 106: Design and implement multi-tenant architecture
Output: System supporting multiple isolated tenants
Day 107: Add tenant isolation and resource quotas
Output: Resource limits enforced by tenant
Day 108: Implement tenant-specific configurations
Output: Per-tenant customization capabilities
Day 109: Create tenant onboarding/offboarding processes
Output: Automated tenant provisioning and cleanup
Day 110: Add tenant usage reporting and billing
Output: Usage-based billing system with detailed reports
Day 111: Implement single sign-on integration
Output: SSO support for popular providers (Google, Okta)
Day 112: Create enterprise integration features (LDAP, Active Directory)
Output: Enterprise authentication integration
Week 17: Storage and Retention Management
Day 113: Implement tiered storage for log data
Output: Automatic movement of logs between storage tiers
Day 114: Add data lifecycle policies
Output: Policy-based data management across its lifecycle
Day 115: Create historical data archiving
Output: Archiving system for long-term storage
Day 116: Implement data restoration from archives
Output: Process for retrieving archived logs when needed
Day 117: Add storage optimization for cost reduction
Output: Automated storage optimization with cost metrics
Day 118: Create storage usage forecasting
Output: Predictions of future storage requirements
Day 119: Implement cross-region data replication
Output: Geographic redundancy for disaster recovery
Day 120: Add data sovereignty compliance features
Output: Controls ensuring data stays in designated regions
Module 5: Integration and Ecosystem (Days 121-150)
Week 18: Log Source Integration
Day 121: Create collectors for Linux system logs
Output: Linux agent collecting system and service logs
Day 122: Add Windows event log collection
Output: Windows agent for event log integration
Day 123: Implement cloud service log collection (AWS CloudWatch)
Output: Integration pulling logs from AWS services
Day 124: Add Azure monitoring integration
Output: Connection to Azure Monitor log sources
Day 125: Create Google Cloud logging integration
Output: Integration with Google Cloud Logging
Day 126: Implement container log collection (Docker, Kubernetes)
Output: Container-aware log collection system
Day 127: Add database audit log collection
Output: Collectors for major database audit logs
Week 19: Application Integration
Day 128: Create logging libraries for major languages
Output: Client libraries for Java, Python, Node.js, and .NET
Day 129: Implement structured logging helpers
Output: Tools helping developers create structured logs
Day 130: Add application performance monitoring integration
Output: Combined logs and metrics for application monitoring
Day 131: Create distributed tracing integration
Output: Trace context propagation in logs
Day 132: Implement error tracking features
Output: Automatic grouping and tracking of similar errors
Day 133: Add deployment and release tracking
Output: System correlating logs with software releases
Day 134: Create feature flag status logging
Output: Automatic logging of feature flag state
Week 20: External System Integration
Day 135: Implement Slack notification integration
Output: Alerts and notifications delivered to Slack
Day 136: Add email alerting and reporting
Output: Scheduled and triggered email reports
Day 137: Create PagerDuty/OpsGenie integration
Output: Critical alerts routed to on-call systems
Day 138: Implement JIRA/ServiceNow ticket creation
Output: Automatic ticket creation from log events
Day 139: Add Webhook support for custom integrations
Output: Generic webhook system for third-party services
Day 140: Create data export to S3/blob storage
Output: Automated exports to cloud storage
Day 141: Implement metrics export to monitoring systems
Output: Integration with Prometheus, Datadog, etc.
Week 21: Advanced Processing Integrations
Day 142: Create Elasticsearch integration for advanced search
Output: Log forwarding and querying with Elasticsearch
Day 143: Add Apache Spark integration for big data processing
Output: Spark jobs analyzing log data at scale
Day 144: Implement machine learning pipeline with TensorFlow
Output: ML models trained on log data for prediction
Day 145: Create real-time stream processing with Flink
Output: Complex event processing on log streams
Day 146: Add time series database integration
Output: Metrics extraction and storage in InfluxDB/TimescaleDB
Day 147: Implement business intelligence tool integration
Output: Connections to Tableau, PowerBI, etc.
Day 148: Create natural language queries with NLP
Output: System answering questions asked in plain English
Week 22: Deployment and Operations
Day 149: Build Kubernetes deployment definitions
Output: Complete K8s deployment files for the platform
Day 150: Create cloud-specific deployment templates
Output: Terraform/CloudFormation for AWS, Azure, GCP
Module 6: Specialized Log Processing Use Cases (Days 151-180)
Week 22 (continued): Deployment and Operations
Day 151: Implement GitOps workflow for the platform
Output: CI/CD pipeline with GitOps deployment
Day 152: Create operator pattern for Kubernetes management
Output: Custom K8s operator for the log platform
Day 153: Add infrastructure monitoring integration
Output: Combined infrastructure and log monitoring
Day 154: Implement disaster recovery procedures
Output: Tested DR plan with RTO/RPO measurements
Day 155: Create capacity planning tools
Output: Resource forecasting based on log volume trends
Week 23: Security Log Processing
Day 156: Implement SIEM (Security Information Event Management) features
Output: Security-focused log analysis capabilities
Day 157: Add threat detection rules
Output: Rule engine detecting security threats in logs
Day 158: Create user behavior analytics
Output: System detecting anomalous user behavior
Day 159: Implement IOC (Indicators of Compromise) scanning
Output: Log scanning for known threat indicators
Day 160: Add automated incident response
Output: Playbooks responding to security events
Day 161: Create security compliance reporting
Output: Automated reports for security frameworks (PCI, SOC2)
Day 162: Implement log-based network traffic analysis
Output: Network security monitoring using log data
Week 24: IT Operations Use Cases
Day 163: Build service dependency mapping
Output: Automatic discovery of system dependencies
Day 164: Create change impact analysis
Output: System predicting impacts of changes
Day 165: Implement SLA monitoring and reporting
Output: Real-time SLA tracking with alerting
Day 166: Add capacity management features
Output: Resource usage analysis and forecasting
Day 167: Create automated root cause analysis
Output: System identifying causes of incidents
Day 168: Implement IT asset tracking with logs
Output: Asset inventory derived from log data
Day 169: Build configuration management database integration
Output: CMDB populated with data from logs
Week 25: Business Analytics Use Cases
Day 170: Implement user journey tracking
Output: User flow analysis from application logs
Day 171: Create conversion funnel analysis
Output: Visualization of user conversion steps
Day 172: Add revenue impact analysis
Output: Correlation between system issues and revenue
Day 173: Implement feature usage analytics
Output: Reports showing feature adoption rates
Day 174: Create A/B test analysis framework
Output: Statistical analysis of experiment results
Day 175: Add customer experience monitoring
Output: Metrics for user experience derived from logs
Day 176: Build executive dashboards for business metrics
Output: C-level views of system performance
Week 26: IoT and Edge Log Processing
Day 177: Implement edge log collection for limited connectivity
Output: Log collector working in intermittent network conditions
Day 178: Create bandwidth-efficient log transport
Output: Log shipping optimized for constrained networks
Day 179: Add device state tracking and management
Output: System managing IoT device state from logs
Day 180: Implement geospatial log analysis
Output: Location-based analysis of log events
Module 7: Advanced Distributed Systems Concepts (Days 181-210)
Week 27: Consensus and Coordination
Day 181: Implement Raft consensus algorithm
Output: Working Raft implementation for cluster coordination
Day 182: Create a distributed lock service
Output: Lock service preventing concurrent operations
Day 183: Add distributed semaphores
Output: Resource limiting across distributed components
Day 184: Implement lease-based resource management
Output: Time-bounded ownership of resources
Day 185: Create a service discovery mechanism
Output: Dynamic discovery of system components
Day 186: Add version vectors for conflict resolution
Output: System handling concurrent updates with version vectors
Day 187: Implement a gossip protocol for state dissemination
Output: Efficient information spreading across the cluster
Week 28: Advanced Consistency Models
Day 188: Implement linearizable consistency
Output: Storage system with linearizable guarantees
Day 189: Create causal consistency mechanisms
Output: System preserving causal relationships
Day 190: Add eventual consistency with conflict resolution
Output: System converging despite concurrent updates
Day 191: Implement CRDT (Conflict-free Replicated Data Types)
Output: Data types that automatically resolve conflicts
Day 192: Create tunable consistency levels
Output: API with selectable consistency guarantees
Day 193: Add transaction support across partitions
Output: Cross-partition atomic operations
Day 194: Implement read/write quorums with sloppy quorum
Output: System maintaining consistency during partitions
Week 29: Advanced Fault Tolerance
Day 195: Create a phi-accrual failure detector
Output: Adaptive failure detection system
Day 196: Implement Byzantine fault tolerance
Output: System tolerating malicious nodes
Day 197: Add automatic leader election with prioritization
Output: Leader election preserving important properties
Day 198: Create a consensus-based configuration management
Output: Distributed configuration with atomic updates
Day 199: Implement partition-aware request routing
Output: System maintaining availability during network splits
Day 200: Add multi-region consensus groups
Output: Consensus spanning geographical regions
Day 201: Create a split-brain resolver
Output: System recovering from network partitions
Week 30: Advanced Scalability Patterns
Day 202: Implement intelligent request routing
Output: Request router directing traffic optimally
Day 203: Create adaptive load shedding
Output: System dropping less important work under load
Day 204: Add predictive resource scaling
Output: Scaling before resource exhaustion occurs
Day 205: Implement data rebalancing for even distribution
Output: System redistributing data as cluster changes
Day 206: Create workload-aware partitioning
Output: Partitioning scheme adapted to access patterns
Day 207: Add multi-dimensional sharding
Output: Data sharded by multiple attributes simultaneously
Day 208: Implement locality-aware data placement
Output: Data placement optimizing for access locality
Week 31: Real-time Processing Optimizations
Day 209: Create time-series optimized storage
Output: Storage format specialized for time-series data
Day 210: Implement real-time aggregation with decay functions
Output: Aggregates giving more weight to recent data
Module 8: System Observability and Testing (Days 211-240)
Week 31 (continued): Real-time Processing Optimizations
Day 211: Add approximate query processing for speed
Output: Fast approximate answers for large-scale queries
Day 212: Create pre-computed aggregates and materialized views
Output: Accelerated queries using pre-computed results
Day 213: Implement streaming window joins
Output: Real-time joining of different event streams
Week 32: Advanced Monitoring
Day 214: Build a metrics collection framework
Output: System collecting metrics from all components
Day 215: Create service-level objective tracking
Output: SLO/SLI monitoring with alerting
Day 216: Add distributed tracing for request flows
Output: End-to-end request tracing across components
Day 217: Implement advanced log correlation
Output: Automatic correlation of related log events
Day 218: Create anomaly detection for system metrics
Output: Automatic detection of unusual system behavior
Day 219: Add predictive failure analysis
Output: System predicting failures before they happen
Day 220: Implement dependency-aware monitoring
Output: Monitoring system understanding service relationships
Week 33: Testing and Verification
Day 221: Create distributed system test framework
Output: Framework for testing distributed components
Day 222: Implement property-based testing
Output: Tests verifying system properties under random inputs
Day 223: Add chaos engineering capabilities
Output: Tools for injecting controlled failures
Day 224: Create partition testing tools
Output: Tests for system behavior during network partitions
Day 225: Implement clock skew testing
Output: Tests for system behavior with unsynchronized clocks
Day 226: Add load and stress testing framework
Output: System for testing performance under extreme load
Day 227: Create long-running reliability tests
Output: Tests verifying stability over extended periods
Week 34: Performance Analysis
Day 228: Build a distributed profiling system
Output: Profiler capturing performance across components
Day 229: Implement distributed request tracing
Output: Detailed latency breakdown for requests
Day 230: Add flame graph generation for bottleneck analysis
Output: Visualizations showing processing bottlenecks
Day 231: Create benchmark suite for key operations
Output: Standardized benchmarks for system capabilities
Day 232: Implement A/B performance testing
Output: Framework comparing performance of alternatives
Day 233: Add resource utilization analysis
Output: Reports identifying resource efficiency
Day 234: Create performance regression detection
Output: Automated detection of performance degradation
Week 35: Debugging and Diagnostics
Day 235: Implement distributed system snapshot capture
Output: Tool capturing global state for debugging
Day 236: Create context-aware log enrichment
Output: Logs automatically enhanced with relevant context
Day 237: Add post-mortem debugging tools
Output: Tools for analyzing system state after failures
Day 238: Implement real-time debugging capabilities
Output: Features for debugging production systems safely
Day 239: Create visualization for distributed executions
Output: Visual representation of distributed processes
Day 240: Add root cause analysis automation
Output: System suggesting likely causes of problems
Module 9: Advanced Performance and Optimization (Days 241-270)
Week 36: Memory and CPU Optimization
Day 241: Implement memory pool allocators
Output: Efficient memory management reducing GC overhead
Day 242: Create lock-free data structures
Output: High-performance concurrent data structures
Day 243: Add CPU cache-friendly algorithms
Output: Optimized algorithms maximizing CPU cache efficiency
Day 244: Implement SIMD optimizations
Output: Performance improvements using vector instructions
Day 245: Create thread affinity management
Output: Thread scheduling optimized for NUMA architectures
Day 246: Add adaptive batch sizing
Output: Self-tuning batch sizes based on system load
Day 247: Implement zero-copy processing pipelines
Output: Processing pipeline eliminating unnecessary copies
Week 37: Storage Optimization
Day 248: Create LSM-tree based storage engine
Output: Storage engine optimized for write-heavy workloads
Day 249: Implement columnar storage for analytics
Output: Column-oriented storage for analytical queries
Day 250: Add bloom filters for membership testing
Output: Efficient filtering using probabilistic data structures
Day 251: Create hierarchical storage management
Output: Automatic data movement between storage tiers
Day 252: Implement incremental compaction strategies
Output: Storage compaction minimizing performance impact
Day 253: Add compression algorithm selection based on data
Output: Adaptive compression using optimal algorithms
Day 254: Create append-only immutable data structures
What are the h/w, s/w pre-reqs - will a Linux laptop or desktop suffice - what configuration?
Is Windows supported?
What programming language is assumed - will Python suffice?
Is there a discussion forum for support - organized by day?
Thanks
Day 32 links to 31, will need correction to the correct article