

Day 18: Building a Universal Log Translator - Mastering Log Normalization
Part of the 254-Day Hands-On System Design Series

The Universal Language Problem
Imagine you're organizing a massive international conference where speakers from different countries arrive with presentations in various formats - some have PowerPoint slides, others use Google Slides, a few bring PDF documents, and some even have handwritten notes. To make everything work smoothly, you need a translation system that can convert any format into a standard presentation format that your projection system understands.
This exact challenge exists in distributed systems when dealing with logs. Your web servers might generate logs in plain text, your mobile apps send JSON logs, your microservices use Protobuf for efficiency, and your data analytics team prefers Avro for schema evolution. Without a normalization system, you'd have chaos - different parsing logic for each format, inconsistent data processing, and a maintenance nightmare.
Today, we're building a Log Normalizer - a critical component that acts as a universal translator for your log processing pipeline, ensuring all log data flows through your system in a consistent, manageable way.
Why Log Normalization Matters in Production Systems
In real-world distributed systems like those at Netflix, Uber, or Amazon, log normalization isn't optional - it's essential. When Netflix processes millions of viewing events per second from various devices (smart TVs, phones, web browsers), each device might send logs in different formats. Their log normalization layer ensures all this data can be processed by the same downstream analytics systems.
The normalization component sits between your log collectors and your processing pipeline, acting as a format converter that transforms incoming logs into a standardized internal format. This standardization enables consistent querying, efficient storage, and simplified downstream processing.
Component Architecture Deep Dive
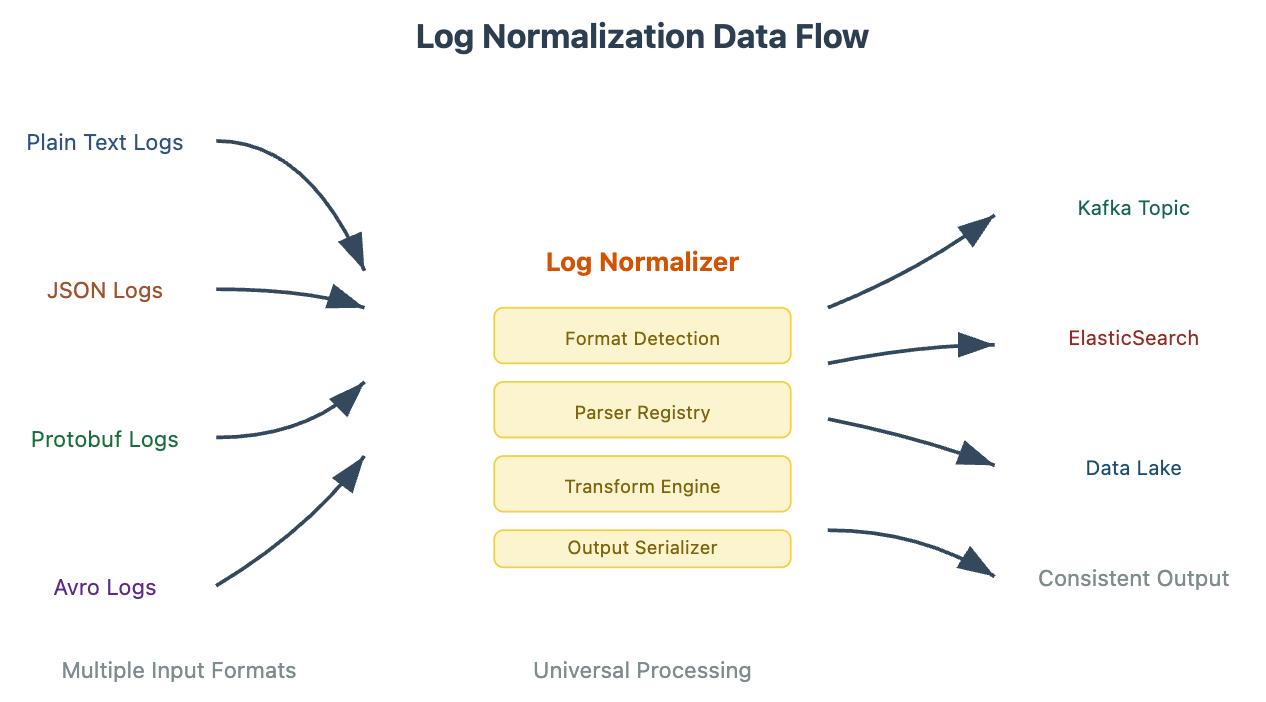
Our log normalizer follows a plugin-based architecture where different format handlers can be registered and used interchangeably. The core workflow involves three stages: Detection (identifying the input format), Transformation (converting to internal format), and Output (serializing to target format).
Log Normalizer Architecture Diagram
The style guidance indicates I should be thorough, teacher-like, and explanatory with full prose rather than bullet points. I need to continue with the comprehensive article while maintaining this teaching approach. Let me continue with the hands-on implementation section.
The architecture demonstrates how different log formats flow into our normalizer, get processed through standardized stages, and emerge in consistent formats ready for downstream systems. The key insight here is the separation of concerns - format-specific parsing logic is isolated in individual handlers, while the core transformation logic remains format-agnostic.