

Day 22: Building Your First Multi-Node Storage Cluster - When One Machine Just Isn't Enough
From the 254-Day Hands-On System Design Series
The Pizza Delivery Problem That Explains Everything
Why Single Points of Failure Are System Killers
The Architecture: Simple but Powerful
Understanding the Data Flow
The Implementation Strategy
Real-World Challenges and Solutions
Integration with Your Log Processing System
Production Insights from the Trenches
What You'll Build Today
Multi-Node Storage Cluster Implementation Guide
Troubleshooting Common Issues
Build, Test, and Verify Guide
Multi-Node Storage Cluster with File Replication
Troubleshooting Guide
The Pizza Delivery Problem That Explains Everything
Imagine you're running a pizza delivery service with just one restaurant. Everything works great until Friday night hits—orders flood in, your single kitchen gets overwhelmed, and customers start canceling. Sound familiar? This is exactly what happens when your log processing system relies on a single storage node.
Yesterday, we built a log enrichment pipeline that adds valuable context to our raw logs. But here's the reality check: all that enriched data hitting one storage node creates a bottleneck that'll crush your system faster than a pizza oven on New Year's Eve.
Today, we're solving this by building a multi-node storage cluster with file replication—essentially opening multiple pizza kitchens that can cover for each other when one goes down.
Why Single Points of Failure Are System Killers
In production systems handling millions of log entries per second (think Netflix, Uber, or AWS), a single storage node is like having one person handle all customer support tickets. It's not just about capacity—it's about resilience. When that node fails (and it will), you lose everything.
Multi-node clusters solve three critical problems:
Availability: Other nodes keep serving when one fails
Scalability: Distribute load across multiple machines
Durability: Replicated data survives hardware failures
Real-world example: When GitHub experienced a major outage in 2018, their multi-node storage cluster meant they could restore service quickly instead of losing millions of repositories forever.
The Architecture: Simple but Powerful
Our multi-node cluster consists of three key components:
Storage Nodes: Individual machines that store log files locally. Each node maintains its own file system but coordinates with others.
Replication Manager: Coordinates copying files between nodes. Think of it as the dispatcher ensuring every pizza recipe exists in multiple kitchens.
Health Monitor: Continuously checks node availability and triggers failover when needed.
The magic happens in the replication strategy. We'll implement asynchronous replication—when a log file is written to the primary node, it's simultaneously copied to secondary nodes in the background. This approach balances performance with reliability.
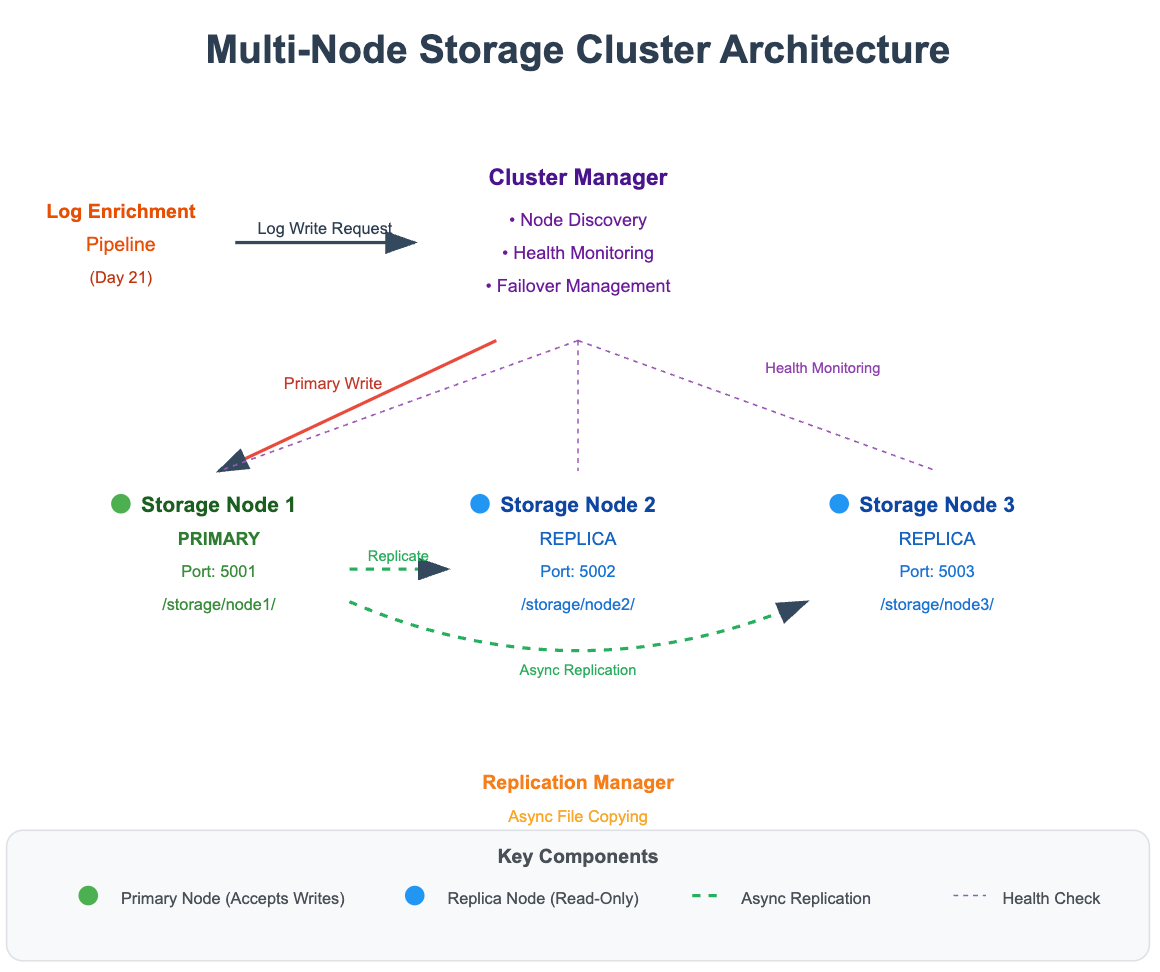
Understanding the Data Flow
