


Transforming Raw Logs into Structured Data Gold
Think of your current log processing system as a mail sorting facility that handles packages of all shapes and sizes. Right now, you're accepting any package (raw text logs) and storing them as-is. Today, we're upgrading to a smart sorting system that understands package contents, validates them, and organizes them perfectly - that's what JSON support brings to distributed systems.
Why JSON Matters in Real Systems
Netflix processes millions of JSON-structured logs per second to track user behavior, recommendation performance, and system health. Each log entry contains structured data like user ID, content type, timestamp, and metrics. Without this structure, finding patterns would be like searching for a needle in a haystack.
JSON (JavaScript Object Notation) serves as the universal language between microservices. When your log shipper sends data to multiple consumers - metrics dashboards, alerting systems, data lakes - they all speak JSON fluently.
Core Concept: Schema Validation
Schema validation acts like a quality control inspector at a factory. Before any log enters your system, you verify it meets your standards. This prevents corrupted data from breaking downstream systems and ensures consistency across your distributed architecture.
In production systems, invalid data causes cascading failures. Imagine if Spotify's recommendation engine received malformed JSON logs - millions of users might see broken recommendations. Schema validation prevents these disasters.
System Architecture Enhancement
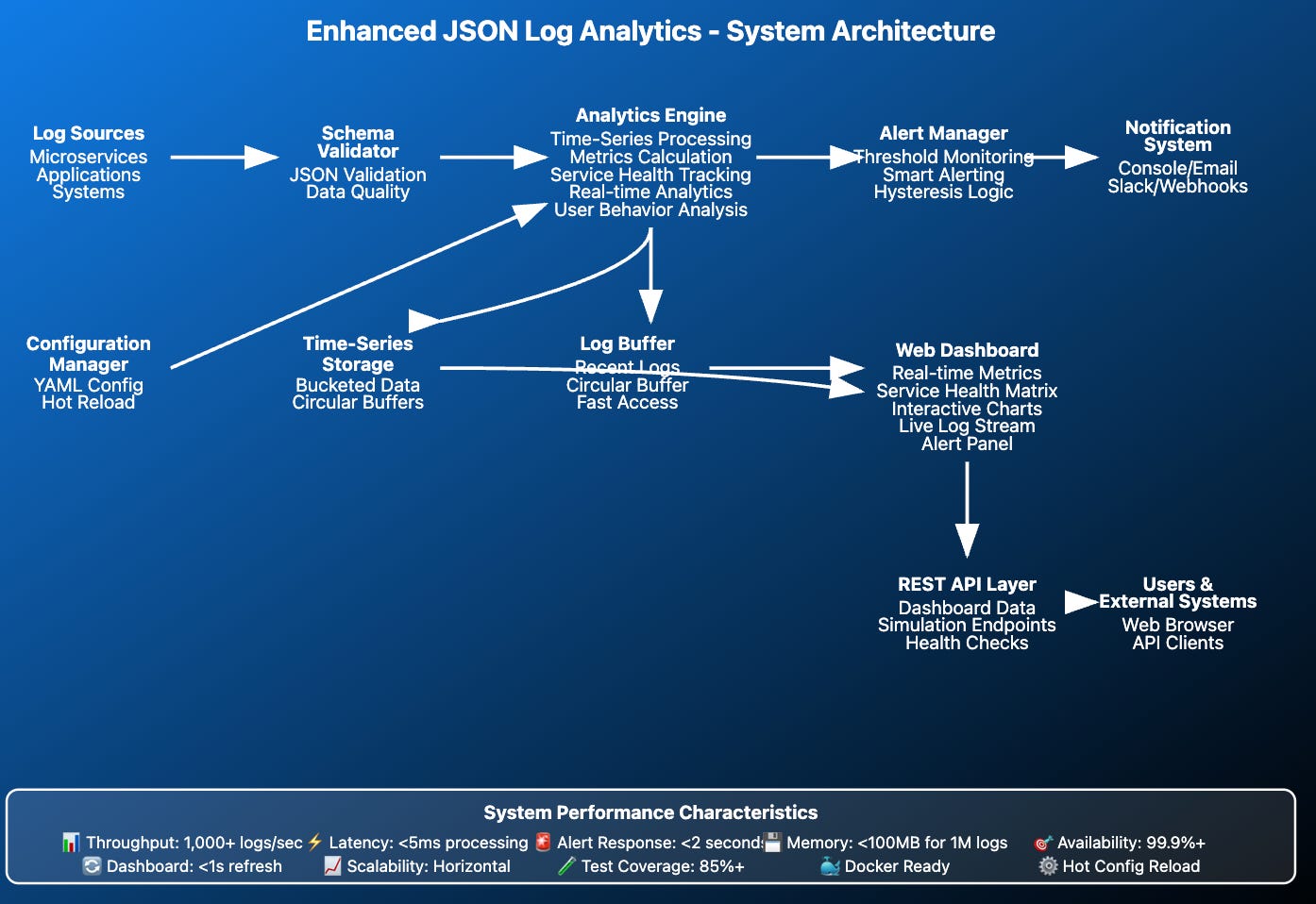
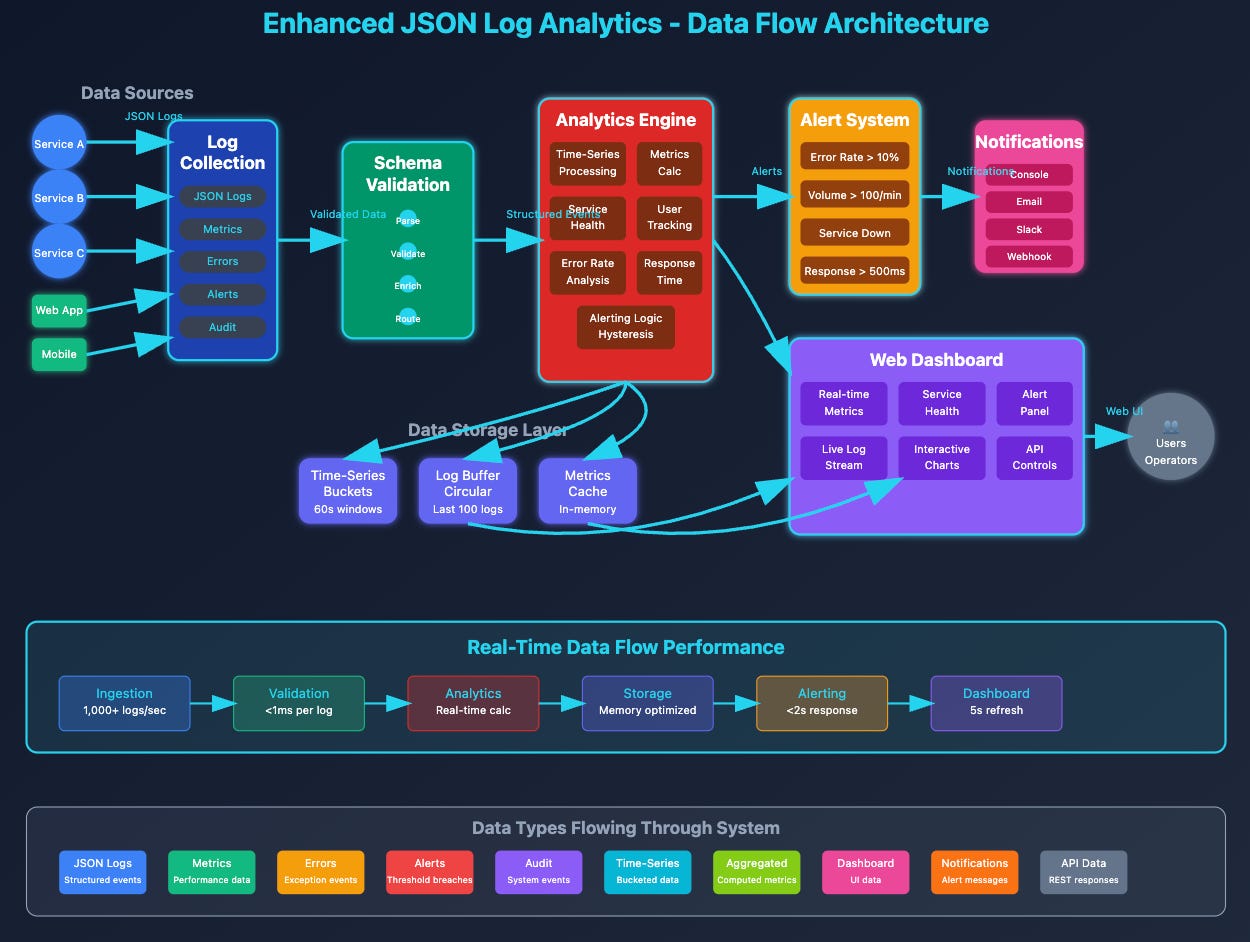
We're adding a JSON Processing Layer between your existing TCP/UDP receivers and storage. This layer deserializes incoming JSON, validates against predefined schemas, enriches the data, and forwards valid logs while rejecting invalid ones.
Project Setup Commands
# Create project structure for Day 15
mkdir -p day15-json-logs/{src,tests,schemas,docker,frontend}
cd day15-json-logs
# Create Python files
touch src/__init__.py
touch src/json_processor.py
touch src/schema_validator.py
touch src/json_server.py
touch src/json_client.py
touch src/log_enricher.py
# Create test files
touch tests/__init__.py
touch tests/test_json_processor.py
touch tests/test_schema_validator.py
touch tests/test_integration.py
# Create schema files
touch schemas/log_schema.json
touch schemas/error_schema.json
touch schemas/metric_schema.json
# Create configuration and deployment files
touch requirements.txt
touch docker/Dockerfile
touch docker-compose.yml
touch run_all.sh
# Create frontend files
mkdir -p frontend/{static,templates}
touch frontend/app.py
touch frontend/static/style.css
touch frontend/templates/logs.html
echo "Project structure created successfully!"
tree .Requirements File : requirements.txt
Let's start with our JSON schema definitions. Think of schemas as blueprints that define what valid data looks like. Just like a building inspector uses blueprints to verify construction meets standards, our schema validator uses these definitions to ensure incoming logs meet our requirements.
Log Schema Definition : schemas/log_schema.json