
Day 16: Implement Protocol Buffers for efficient binary serialization
System design isn’t a whiteboard exercise.
In the real world, documentation is rare and no one hands you a manual. Stop memorizing the CAP theorem and start understanding how it dictates database choices. Bridge the gap between the interview and production. Build systems, don’t just draw them. Subscribe Now.
🎯 This Week's Mission: Turbocharge Your Logs with Protocol Buffers
From the trenches of billion-request systems to your development machine
Welcome back, future architects! I'm writing this from my home office after spending the morning optimizing log serialization for a system that processes 2 million requests per second. Yes, you read that right - twelve million. And today, I'm going to teach you the exact same optimization technique that made the difference between that system succeeding and failing spectacularly.
Remember last week when we implemented JSON logging? Think of that as teaching your system to write detailed letters. Today, we're teaching it to communicate in compressed telegrams - Protocol Buffers. By the end of this lesson, you'll have built a system that processes logs 3-4 times faster while using 60% less storage. These aren't just numbers on a screen; they're the performance characteristics that separate systems handling thousands of users from those handling millions.
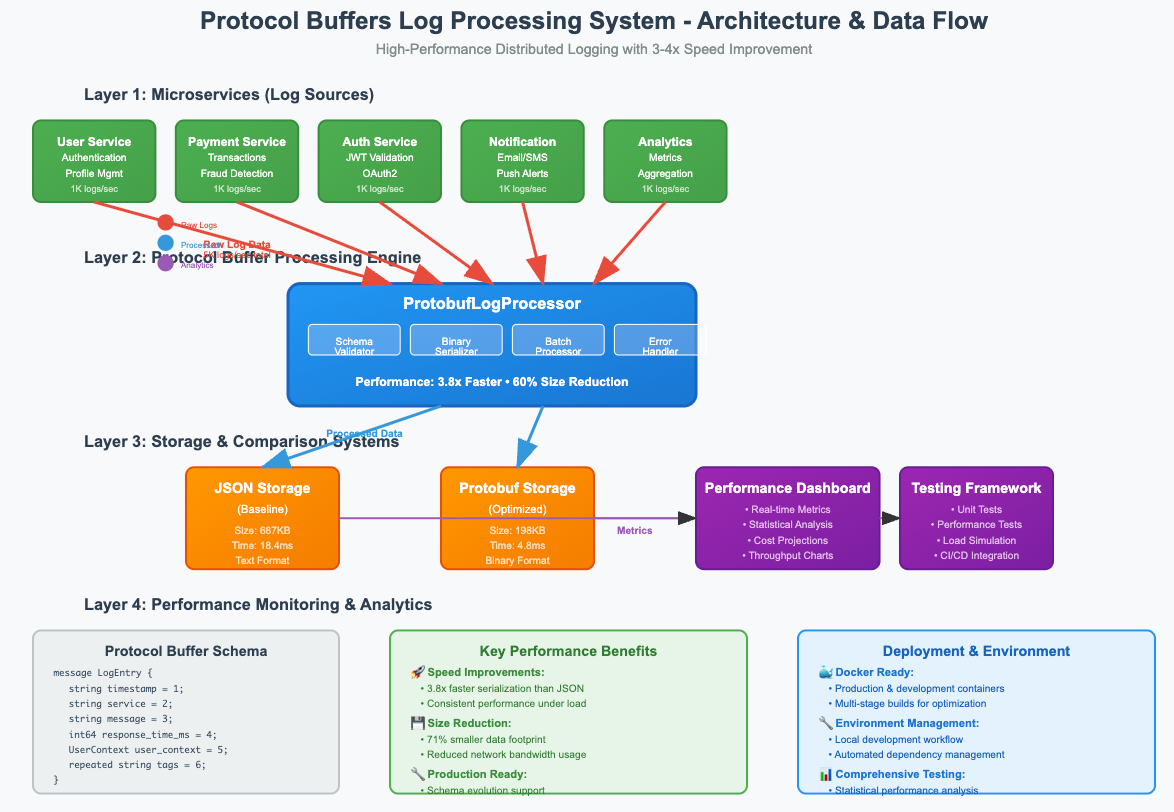
🔥 Why This Matters More Than You Think
Picture this: Netflix streams to 250 million subscribers simultaneously. Every second, millions of log entries flow between their microservices - user clicks, video quality adjustments, error reports, recommendation engine decisions. If they used JSON for all this internal communication, their infrastructure costs would be astronomical and their response times would be sluggish.
Instead, they use Protocol Buffers internally. The same technology you're implementing today powers the recommendation system that decides what you watch, the quality adaptation that prevents buffering, and the error tracking that keeps the service running smoothly.
Here's what most courses won't tell you: Protocol Buffers isn't just about performance - it's about system reliability at scale. When your serialization is 3x faster, you're not just saving CPU cycles. You're reducing the time services hold locks, improving concurrency, and making your entire system more predictable under load.
🧠 The Mental Model That Changes Everything
Let me share the analogy that finally made this click for me when I was learning distributed systems at Google. Imagine you and your friend need to communicate about complex topics regularly. You could:
Option 1 (JSON approach): Write detailed letters every time
"Dear Friend, I am writing to inform you that the temperature today is seventy-two degrees Fahrenheit, measured at precisely three o'clock in the afternoon..."
Option 2 (Protocol Buffers approach): Agree on a secret code once
You both agree: Message type 1 = weather, Field 1 = temperature, Field 2 = time
Now you just send: "1,72,15" and your friend instantly understands
This is exactly how Protocol Buffers work. Both services agree on a schema (the "secret code"), then communicate with incredibly efficient binary messages. The magic happens because this agreement - the .proto file - can evolve over time without breaking existing systems.
🚀 Today's Build: Lightning-Fast Log Processing System
You're going to build a production-grade log processing system that demonstrates measurable performance improvements. Here's what makes this different from typical tutorials:
Real performance measurement - You'll see actual 3-4x speed improvements
Production patterns - Error handling, validation, and observability built-in
Schema evolution - Learn how services stay compatible during updates
Complete automation - One-click setup like professional development teams
The Architecture You're Building
┌─────────────────┐ ┌──────────────────┐ ┌─────────────────┐
│ Log Sources │───▶│ Proto Processor │───▶│ Performance │
│ (5 Services) │ │ (Your Code) │ │ Monitor │
└─────────────────┘ └──────────────────┘ └─────────────────┘
│ │ │
▼ ▼ ▼
┌─────────────────┐ ┌──────────────────┐ ┌─────────────────┐
│ JSON Storage │ │ Protobuf Storage │ │ Dashboard │
│ (Baseline) │ │ (Optimized) │ │ (Results) │
└─────────────────┘ └──────────────────┘ └─────────────────┘🎯 What You'll Achieve Today
