
Week 4 : Integrated - Build a Distributed Log Storage Cluster — Replication, Quorums, and Repair
What we build today
By the end of this lesson you will run a three-node log storage cluster that:
Partitions logs by source or time
Places replicas with consistent hashing
Commits writes with quorum (W=2) and reads with quorum (R=2)
Queries ERROR logs across partitions
Runs anti-entropy (Merkle diff + repair)
Shows live metrics on a dashboard — click Run Demo to add more data
Success criteria: Dashboard ingested and repairs_completed increase after each Run Demo; /metrics last_update changes every second.
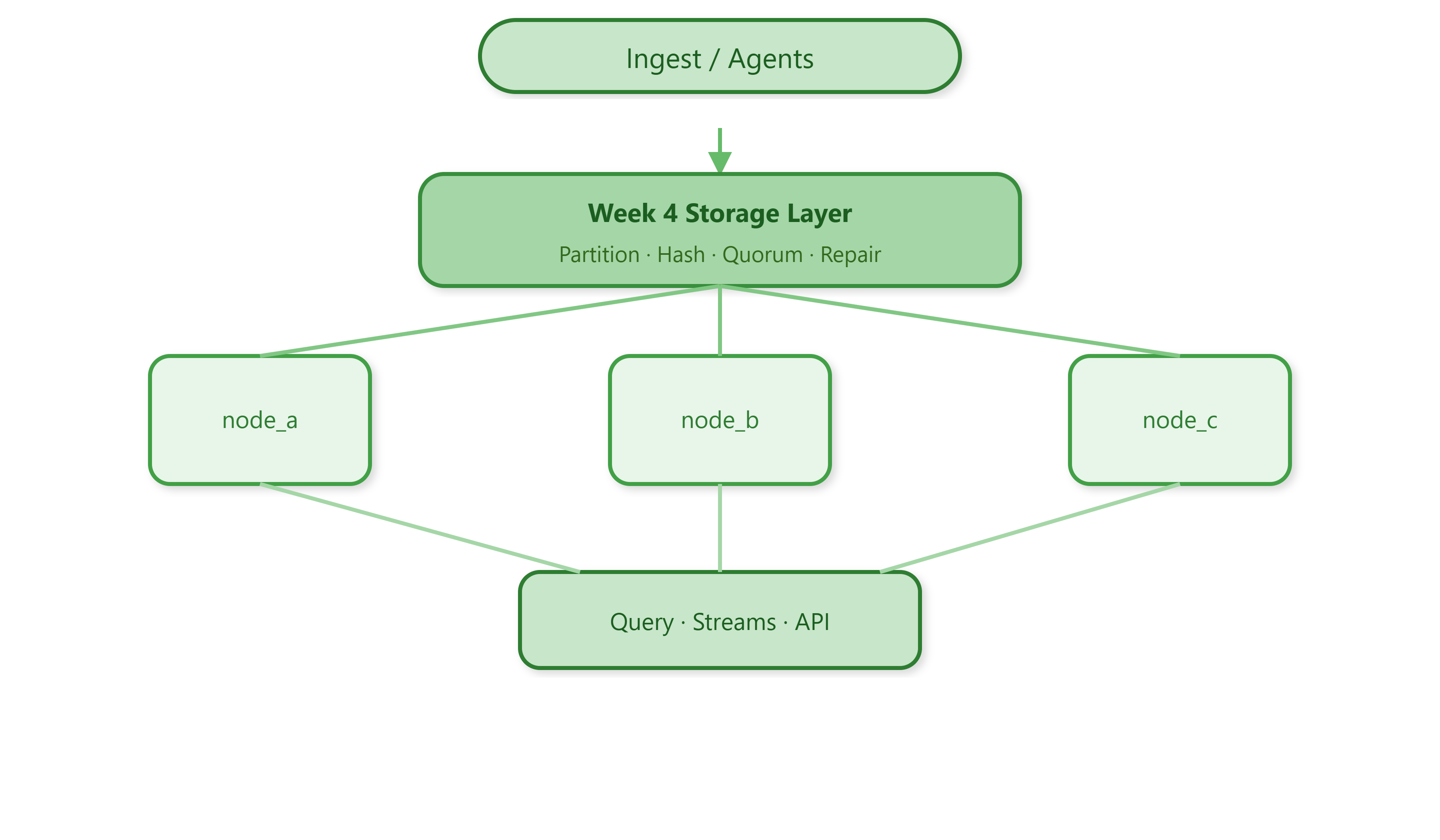
Where this sits in the full system
Week 4 is the storage spine of our 254-day log platform. Upstream weeks ingest and serialize logs; downstream weeks add Kafka, search, and APIs. Today you own where bytes live, how many copies exist, and how the cluster heals drift — the same problems Cassandra, Dynamo-style KV, and log shard managers solve at billion-event scale.
Core concepts (non-obvious insights)
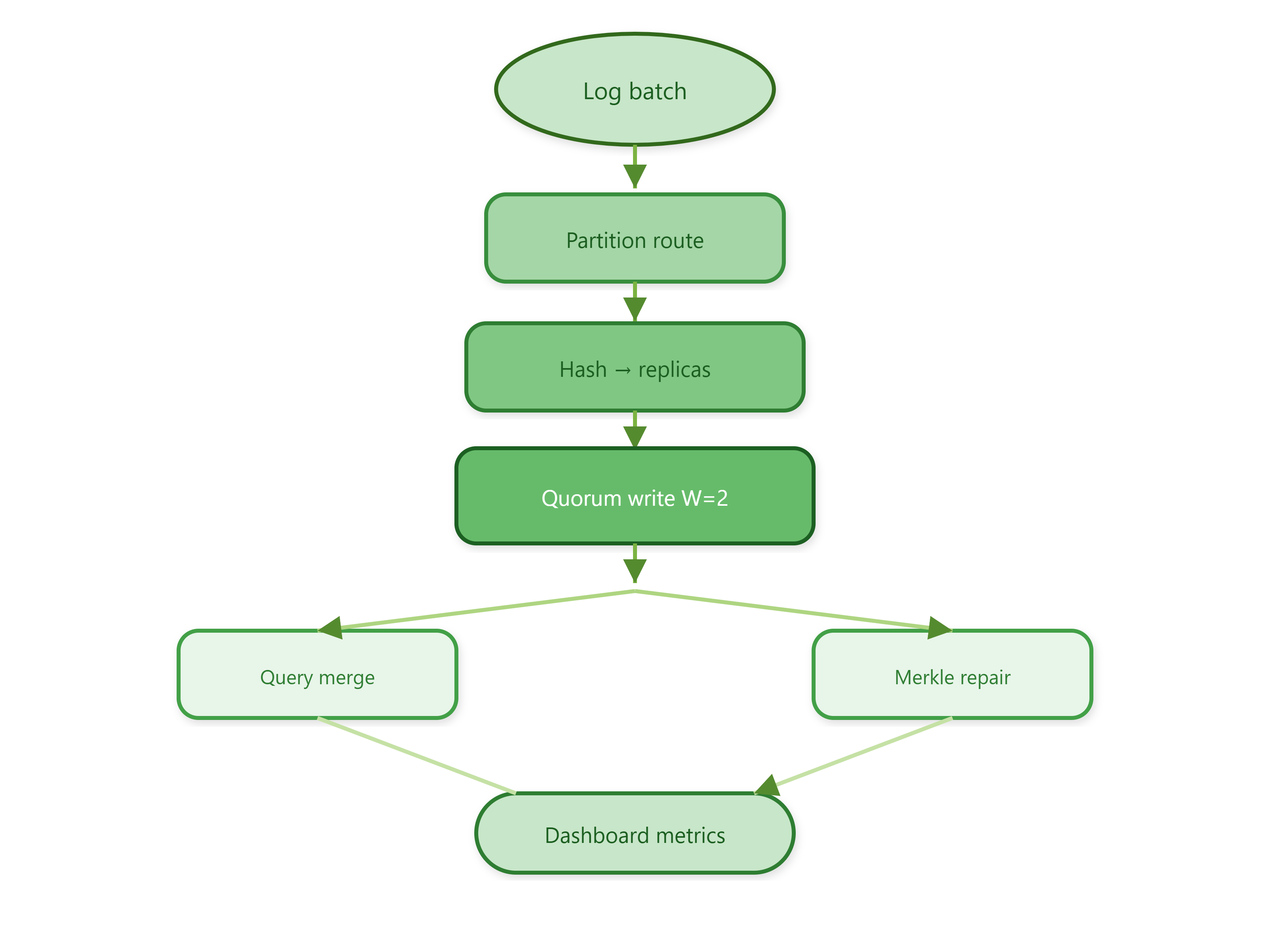
Partitioning ≠ sharding keys. Partitioning decides which slice owns a log for queries; consistent hashing decides which physical nodes hold replicas. Confusing them causes “balanced partitions but hot nodes.”
Quorum is a latency contract. W=2 of 3 means one slow replica still allows writes — but you must design read repair or anti-entropy so the lagging copy catches up. Production systems expose tunable R/W like Cassandra’s ONE / QUORUM / ALL.
Anti-entropy is not a luxury. At LinkedIn-scale ingestion, bit rot, partial writes, and restarts leave silent divergence. Merkle trees compare digests cheaply before shipping full datasets — the same idea behind Dynamo’s hinted handoff follow-up repairs.
Preparing for a distributed systems interview?
→Download the free Interview Pack
→ Subscribe now to access source code repository - 200 + coding lessons
