
Week 6: Stream Processing with Kafka — “Turn log floods into live intelligence”
What we’re building today
When Uber ships a million ride events per minute, nobody waits for a batch job at midnight. Kafka sits in the middle—absorbing spikes, fanning work to parallel consumers, and feeding live dashboards.
By the end of this lesson you’ll have:
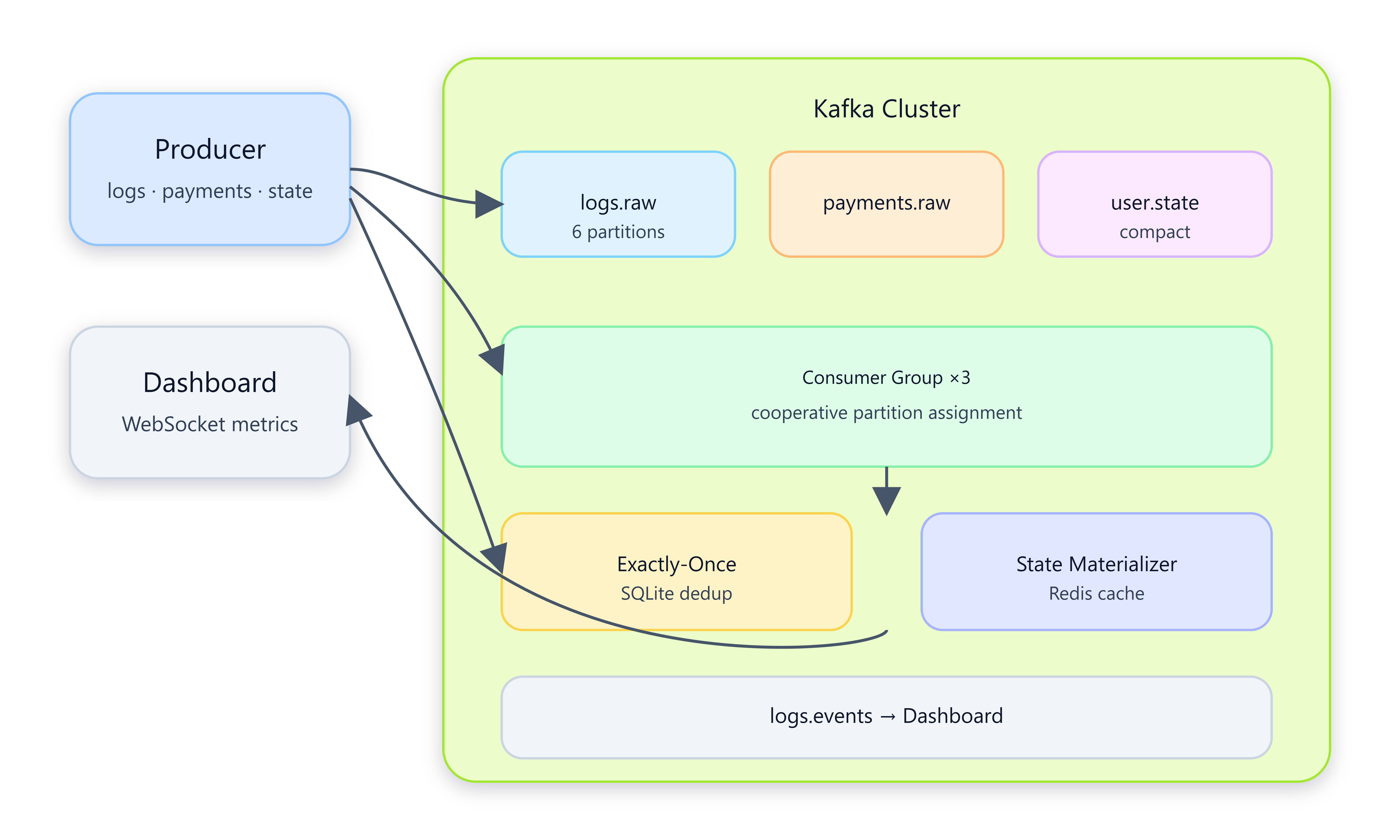
A Kafka cluster with partitioned log topics
Idempotent producers + a 3-worker consumer group
Exactly-once payment processing (SQLite dedup)
Compacted user-state topic
A live stream dashboard (WebSocket metrics)
Why this matters
LinkedIn invented Kafka because their batch pipelines couldn’t keep up with clickstream volume.
Netflix uses stream processors to detect playback failures within seconds—not hours.
Stripe treats duplicate payment events as a money bug; idempotent consumers are non-negotiable.
Queues buffer bursts. Streams let you react while data is still moving.
Core concept
Topic = named log. Partition = parallel lane. Consumer group = team of workers splitting lanes.
One log event’s journey:
Producer → logs.raw [partition 2] → consumer-2 → logs.events → Dashboard chart
Exactly-once adds: “Have I seen this payment ID before?” before touching the database.
Architecture
Preparing for a distributed systems interview?
→Download the free Interview Pack
→ Subscribe now to access source code repository - 200 + coding lessons
