
Week 5: Message Queues for Log Processing
What we’re building today
Picture a game server that suddenly goes viral. In 60 seconds, it goes from 200 players to 20,000. The server starts printing logs like crazy:
“player joined”
“match started”
“payment failed”
“suspicious login”
If your log processor can’t keep up, you don’t just lose “nice-to-have” messages. You lose the exact clues you need to debug the outage.
Today you’re building a simple, real system that prevents that: a queue-backed log pipeline using RabbitMQ.
By the end of this lesson, you’ll have:
A producer that publishes structured logs
RabbitMQ routing (direct/topic/fanout) and durable queues
A worker that processes logs with ACK, retry, and DLQ
Priority handling for critical logs
A dashboard that shows queue counts and a live “processed / retry / dlq” stream
Why this matters
Netflix and YouTube-style systems don’t send every event directly to “the one processor.” They buffer bursts so the system keeps breathing.
Banks retry payments when a downstream system times out—your logs deserve the same reliability.
Security teams care about the 0.1% of logs that indicate an attack. Priority queues keep those from waiting behind low-value noise.
This isn’t “extra engineering.” It’s the difference between “we saw the failure” and “we’re guessing.”
Core concept
Instead of:
App → Processor
You build:
App → Queue → Processor
The queue is like a waiting room. The app can keep sending messages quickly, and the worker can process them at a steady pace.
Two important rules make this safe:
ACK: the worker says “I’m done” only after processing succeeds
Retry + DLQ: if something goes wrong, the message is tried again later; if it keeps failing, it’s quarantined
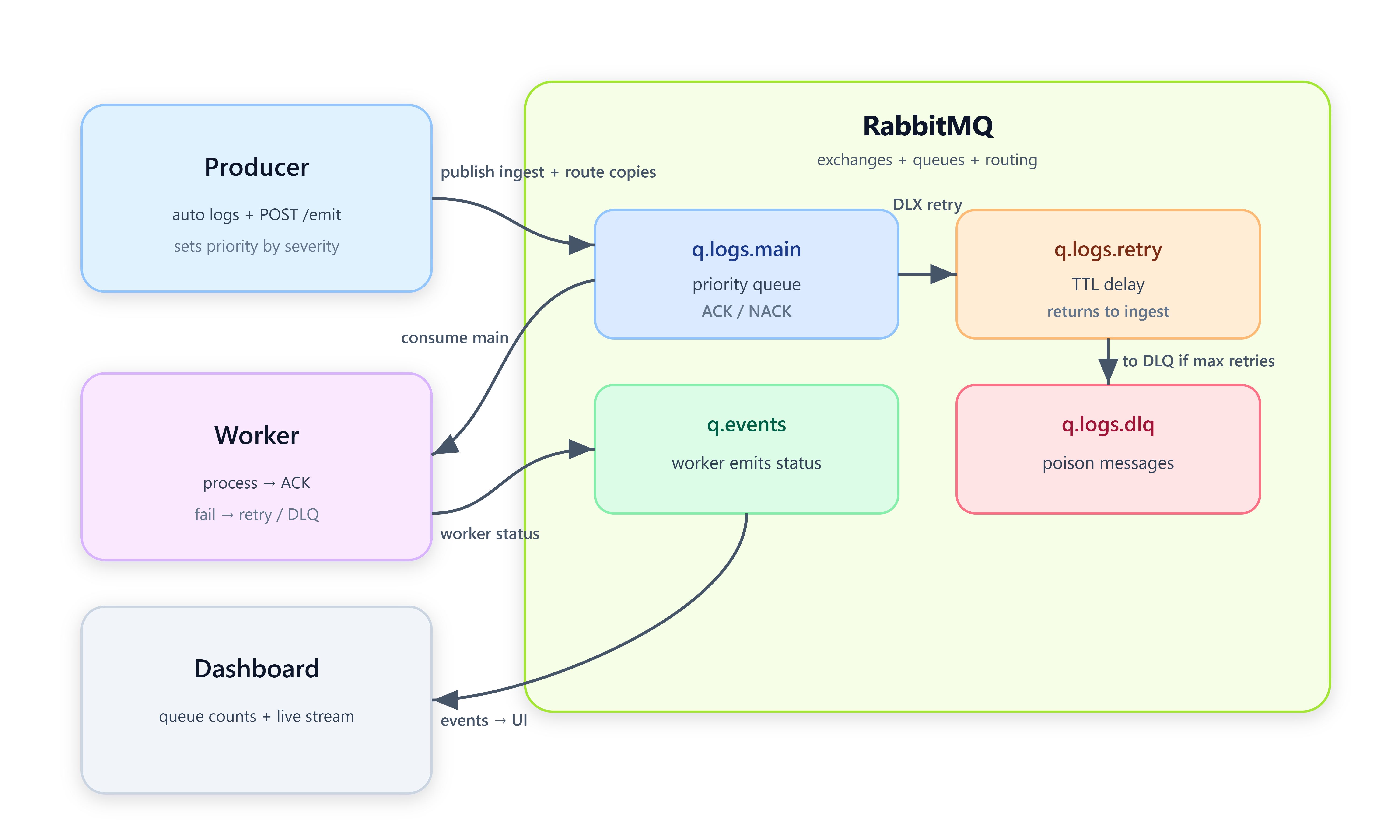
Architecture
Preparing for a distributed systems interview?
→Download the free Interview Pack
→ Subscribe now to access source code repository - 200 + coding lessons
