
Day 62: Implement Backpressure Mechanisms for Load Management
What We’re Building Today
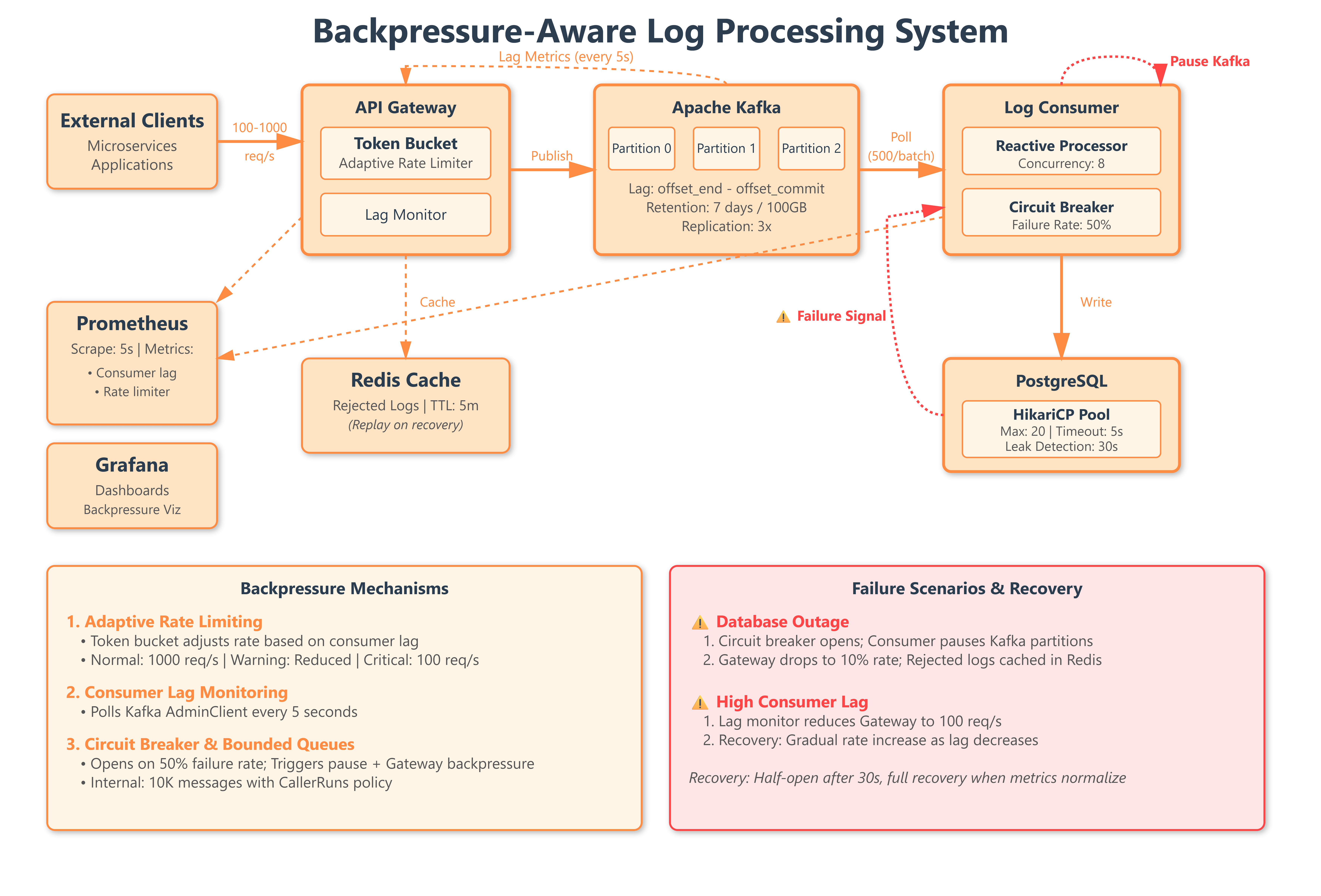
Today, we’re implementing production-grade backpressure mechanisms that protect our distributed log processing system from overload:
Adaptive rate limiting with token bucket algorithms at the API gateway
Kafka consumer lag monitoring with automatic throughput throttling
Circuit breaker integration that triggers backpressure when downstream services degrade
Reactive backpressure using Spring WebFlux for non-blocking flow control
Why This Matters: The Cost of Ignoring Backpressure
In 2020, a major e-commerce platform experienced a cascading failure during Black Friday when their log aggregation system accepted more events than it could process. Without backpressure, their Kafka consumers fell 2 hours behind, Redis caches expired prematurely, and the entire observability stack collapsed—leaving teams blind during their highest-traffic day.
Backpressure isn’t about rejecting work; it’s about controlled degradation. When Netflix’s API gateway detects rising latencies, it doesn’t crash—it applies backpressure to preserve core functionality. Uber’s real-time dispatch system uses backpressure to ensure that even during surge demand, critical ride matching continues while less critical analytics can lag.
The fundamental challenge: distributed systems have no single point of control. A producer publishing 100K logs/second doesn’t know that downstream consumers can only handle 20K. Without backpressure, queues grow unbounded, memory exhausts, and the system fails catastrophically.
System Design Deep Dive: Backpressure Patterns
Preparing for a distributed systems interview?
→Download the free Interview Pack
→ Subscribe now to access source code repository - 200 + coding lessons
