
Day 60: Multi-Region Replication for Log Data
What We’re Building Today
Yesterday you implemented active-passive failover so critical components recover automatically. Today, you’re taking that foundation and turning it into a globally replicated log pipeline — the backbone of every major cloud-native observability stack in production.
By the end of this lesson you will have:
A multi-region Kafka replication topology that mirrors log events across two simulated geographic regions using MirrorMaker 2
A conflict-resolution strategy for out-of-order and duplicate events that arrive from separate regions during a split-brain scenario
Region-aware routing in the API Gateway that directs producers to the nearest region while keeping consumers globally consistent
End-to-end monitoring that surfaces replication lag, cross-region throughput, and divergence alerts in Grafana
Why This Matters
A single-region log system is an availability bet. The moment your datacenter loses power, your network partition hits, or your cloud provider has an outage affecting one zone, every log event generated during that window is either lost or delayed — and in observability, delayed logs are nearly as dangerous as missing logs because they break correlation windows used for incident diagnosis.
Multi-region replication is how Netflix kept its recommendation engine’s telemetry flowing during the 2012 US East outage, how Uber surfaces driver GPS traces in the nearest region while guaranteeing global query consistency, and how Amazon’s Route 53 health checks keep log ingestion alive across continents. The pattern is deceptively simple in marketing materials — “we just replicate” — but the engineering trade-offs around consistency, ordering, and deduplication are where real system designers earn their credibility. Today you’ll wrestle with those trade-offs hands-on.
System Design Deep Dive
Preparing for a distributed systems interview?
→Download the free Interview Pack
→ Subscribe now to access source code repository - 200 + coding lessons
1. Replication Topology: Active-Active vs. Active-Passive
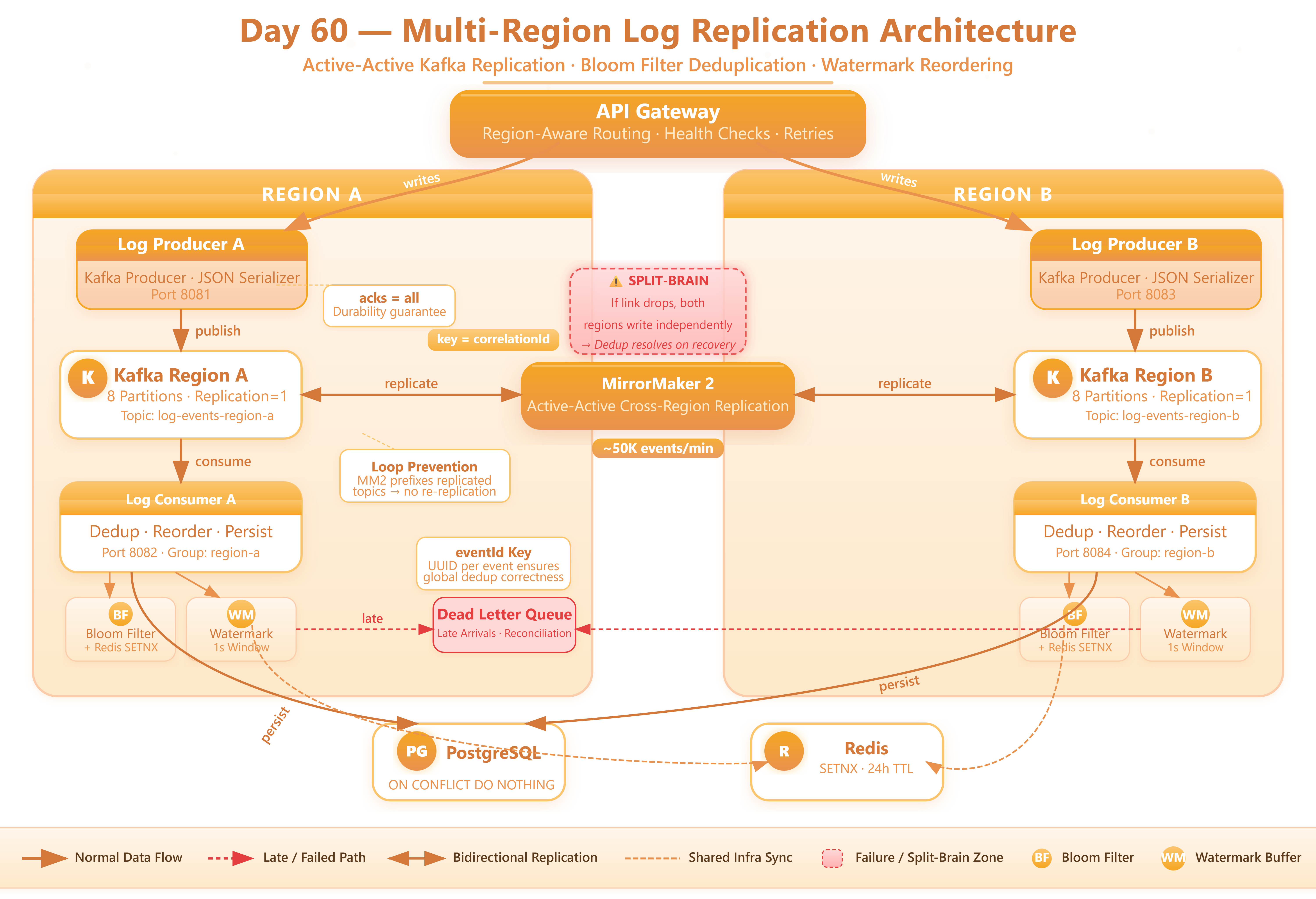
Day 59 gave you active-passive failover within a single region. Multi-region replication forces a harder question: do both regions write simultaneously, or does one region always own the write path?
Active-passive replication keeps things simple. Region A is the primary; Region B is a hot standby that receives replicated data but does not accept producer writes under normal conditions. Failover promotes Region B to primary. The cost: Region B’s logs are always behind by the replication lag, so during a failover you accept a small window of potential data loss (RPO).
Active-active replication lets both regions accept writes simultaneously and cross-replicate. Throughput doubles and RPO drops to near-zero, but you immediately introduce the split-brain problem: if the replication link between regions fails, both regions continue accepting writes independently. When the link recovers, you have two divergent histories and must merge them.
For a log processing system, active-active is almost always the right call. Logs are append-only, high-volume, and latency-sensitive. The deduplication cost of merging after a split is far less than the cost of dropping events during an outage. Today’s implementation uses active-active with idempotency-key-based deduplication at the consumer layer to resolve conflicts.
Architectural Insight: Kafka’s MirrorMaker 2 was designed for active-active. It uses topic-offset translation to prevent replication loops — Region A’s copy of Region B’s topic is tagged with a source prefix, so MirrorMaker in Region B does not re-replicate it back. Understanding this loop-prevention mechanism is what separates a working multi-region Kafka setup from one that spirals into infinite replication.
2. Ordering Guarantees Across Regions
Kafka guarantees ordering within a partition on a single broker. Cross-region replication shatters that guarantee. An event produced in Region A at T=100ms may arrive in Region B at T=250ms, but an event produced in Region B at T=180ms is already sitting in Region B’s partition at T=180ms. A consumer reading Region B’s merged topic sees events out of order relative to their original production time.
The standard mitigation is a watermark-based reorder buffer at the consumer. Each consumer maintains a sliding window (configurable, typically 500ms–2s) and holds events until it’s confident no earlier event will arrive from the other region. Events older than the watermark are flushed in order; events that arrive after the watermark has passed are flagged as late arrivals and routed to a dead-letter partition for reconciliation.
This is exactly the pattern used in Google’s Dataflow and Flink’s event-time processing. The trade-off is clear: lower watermark = lower latency, higher risk of out-of-order emissions. Higher watermark = better ordering, higher end-to-end latency. Today’s implementation exposes the watermark as a tunable configuration property so you can observe the effect directly in your load tests.
3. Deduplication Strategy
When both regions accept writes and the replication link recovers after a split, some events will exist in both regions’ topics. A naive consumer will process them twice — which, for a log indexing system, means duplicate entries in your search backend and inflated metrics.
The production pattern is server-side idempotency with a distributed cache. Each log event carries an eventId (a UUID generated by the producer at ingestion time). The consumer checks a Redis-backed bloom filter before processing. If the eventId is already present, the event is silently discarded. Bloom filters give you probabilistic deduplication with near-zero memory overhead — the false-positive rate (roughly 0.01% at our configuration) is an acceptable trade-off for the memory savings versus a full hash set.
Uber’s log platform uses a similar two-tier approach: a fast bloom filter for the hot path, backed by a slower exact-match store for audit trails. You’ll implement both tiers today.
4. Region-Aware Routing
The API Gateway needs to know which region a producer request should target. In a real deployment this is DNS-based (GeoDNS routes to the nearest region). In our simulated environment, the gateway reads a X-Region header and routes accordingly, with a fallback to the local region if the target is unhealthy.
The key design decision here is sticky routing: once a producer is assigned to a region for a given session or logical group (e.g., all logs from a single microservice instance), it should stay on that region until a health event forces migration. This minimizes cross-region replication pressure and keeps event ordering more predictable within a single producer’s stream.
5. Monitoring Replication Health
Replication lag is the single most important operational metric for a multi-region system. If Region B’s consumer offset falls more than 10 seconds behind Region A’s producer offset, you’re approaching your RPO budget. Prometheus scrapes both regions’ Kafka exporters every 15 seconds; Grafana alerts fire when lag exceeds configurable thresholds.
Beyond lag, you need to track replication throughput (bytes/sec crossing the region boundary), split-brain duration (time between network partition and recovery), and deduplication hit rate (percentage of events filtered by the bloom filter). All four metrics are wired into today’s Grafana dashboard.
Implementation Walkthrough
GitHub Link :
https://github.com/sysdr/sdc-java-p/tree/main/day60/day60-multi-region-log-replicationStep 1: MirrorMaker 2 Configuration
The docker-compose.yml spins up two Kafka clusters (kafka-region-a, kafka-region-b) and two MirrorMaker 2 instances. Each MirrorMaker is configured with a source.cluster and target.cluster, and a replication factor of 2. The topic replication policy uses a regex filter (log-events-.*) so only your log topics are mirrored — not internal Kafka topics like __consumer_offsets.
The critical configuration property is replication.lag.max.bytes. Set this too high and your failover RPO balloons. Set it too low and MirrorMaker becomes a bottleneck under peak load. Start at 1MB and tune based on your load test results.
Step 2: Region-Aware Producer
KafkaProducerService now accepts a targetRegion parameter. Under the hood it maintains two KafkaProducer instances — one per region — and selects the appropriate one based on the routing decision from the gateway. If the target region’s producer fails to send within the configured timeout, the service falls back to the local region and logs a REGION_FALLBACK event for monitoring.
Step 3: Watermark Consumer
ReplicationAwareConsumer extends the base consumer with a ReorderBuffer. On each poll cycle, the buffer checks whether the current event’s eventTimestamp is within the watermark window. Events inside the window are held; events outside are emitted to the downstream processor in timestamp order. Late arrivals (events with timestamps older than the current watermark) are sent to the log-events-late dead-letter topic.
Step 4: Bloom Filter Deduplication
DeduplicationService wraps a Guava BloomFilter backed by a Redis HyperLogLog for cross-instance coordination. Each consumer instance maintains its own local bloom filter for speed, and periodically syncs its state to Redis so that if a consumer instance restarts, it can rebuild from the shared state. The sync interval is configurable — 30 seconds is the default, balancing consistency with network overhead.
Step 5: Integration and Load Testing
The load-test.sh script fires 10,000 events split evenly across both simulated regions over 60 seconds, then pauses replication for 5 seconds (simulating a split) and resumes. The integration test suite validates that after recovery, the total unique events processed across both regions equals 10,000 — confirming that deduplication caught all duplicates and the reorder buffer caught all late arrivals.
Working Demo Link :
Production Considerations
Latency budget: MirrorMaker 2 adds 50–200ms of replication latency depending on network distance. If your log consumers have SLAs tighter than that, you need region-local consumption with eventual cross-region consistency, not strong consistency.
Failure mode — MirrorMaker crash: If MirrorMaker goes down, replication stops but both clusters continue accepting writes independently. This is by design. When MirrorMaker restarts, it resumes from the last committed offset. No data is lost; lag temporarily spikes.
Capacity planning: Each region needs enough Kafka broker capacity to handle its own write load plus the full replication load from the other region. In practice, this means sizing each region for roughly 1.8x its expected standalone throughput to account for replication overhead and burst traffic.
Scale Connection
Netflix’s EVIPro (Event Processing Infrastructure) uses a topology nearly identical to what you built today: active-active Kafka clusters across three regions, MirrorMaker 2 for cross-region replication, and a custom deduplication layer at the consumer. Uber’s logging pipeline (documented in their 2021 engineering blog) applies the same watermark-based reorder buffer pattern for GPS event streams that must be globally consistent for driver tracking. Amazon’s CloudWatch Logs uses a similar region-aware routing strategy to keep log ingestion latency under 100ms globally.
This is just the starting point.
The paid content includes advanced lessons, frameworks, templates, practical projects, and deeper explanations to accelerate your learning journey.
Next Steps
Tomorrow: circuit breakers with Resilience4j — how to keep your system healthy when downstream components start failing.