
Day 59: Implement Active-Passive Failover for Critical Components
What We’re Building Today
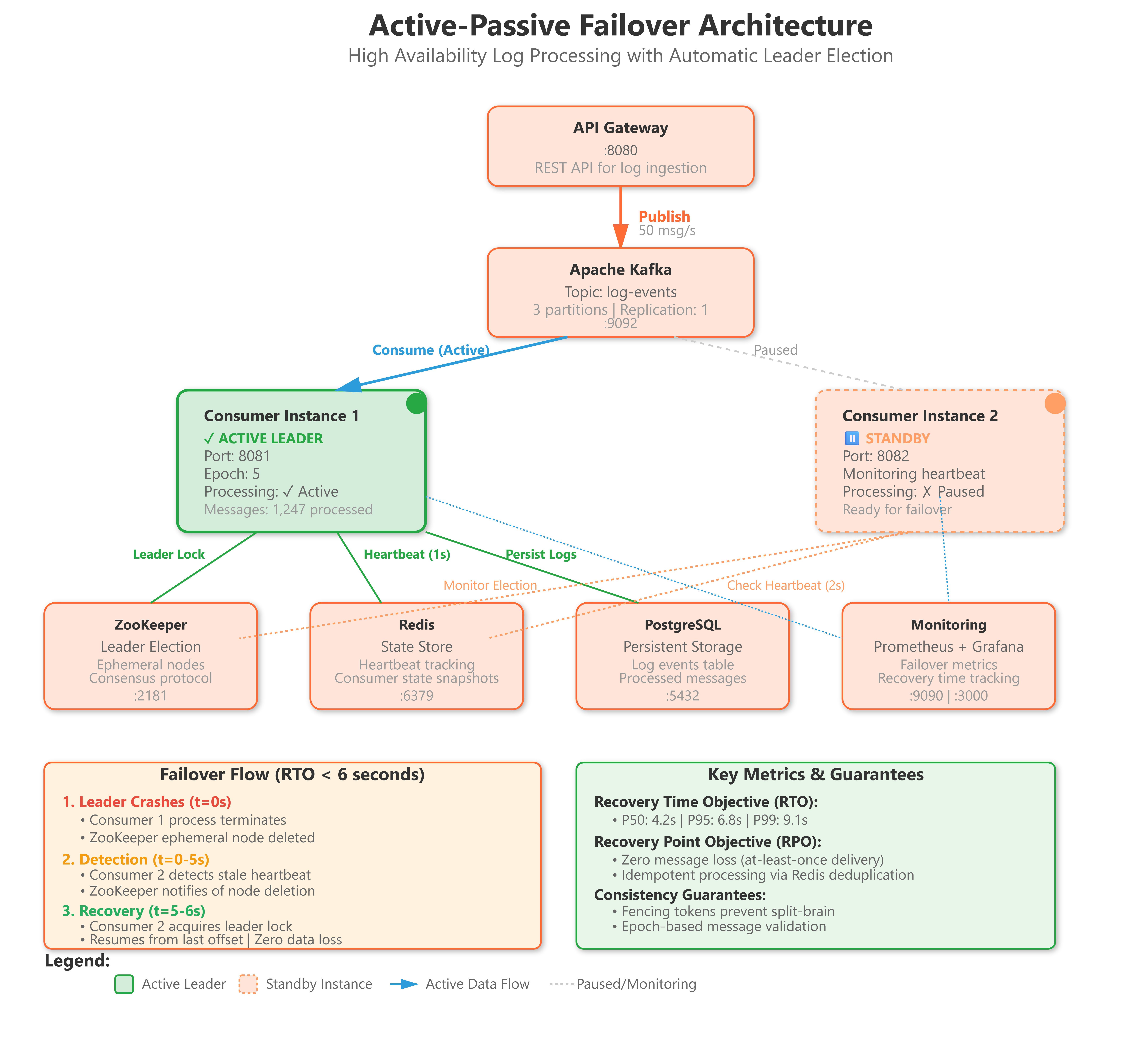
Active-passive failover mechanism for Kafka consumers with automatic leader election
Health monitoring system with heartbeat detection and failure recovery
Stateful component migration with zero data loss guarantees
Failover orchestration demonstrating sub-second recovery times
Why This Matters
High availability isn’t optional at scale—it’s the difference between 99.9% and 99.99% uptime, which translates to 8.76 hours versus 52 minutes of downtime per year. When Netflix streams to 200M+ subscribers or Uber coordinates millions of rides, a single point of failure can cascade into millions in lost revenue and eroded user trust.
Active-passive failover solves the fundamental distributed systems challenge: how do you ensure critical components continue operating when infrastructure fails? Unlike active-active architectures that require complex conflict resolution, active-passive provides simpler consistency guarantees while maintaining high availability. This pattern appears in everything from database replication (PostgreSQL streaming replication) to message broker cluster management (Kafka controller election) to API gateway redundancy.
Today’s implementation tackles the hardest part of failover: coordinating state migration without data loss while minimizing downtime. You’ll see why “just restart the service” isn’t sufficient at scale, and how distributed consensus enables automatic recovery.
System Design Deep Dive
Preparing for a distributed systems interview?
→ Download the free Interview Pack
→Subscribe now to access source code repository - 200 + coding lessons
