

Day 54: Building a SQL-Like Query Language for Distributed Log Search
Module 2: Scalable Log Processing | Week 8: Distributed Log Search

What You'll Master Today
By the end of this lesson, you'll have built a production-ready distributed query system that transforms complex SQL queries into optimized execution plans across multiple nodes. You'll understand the same architectural patterns that power search engines at Google, Netflix, and Amazon.
Today's Learning Agenda:
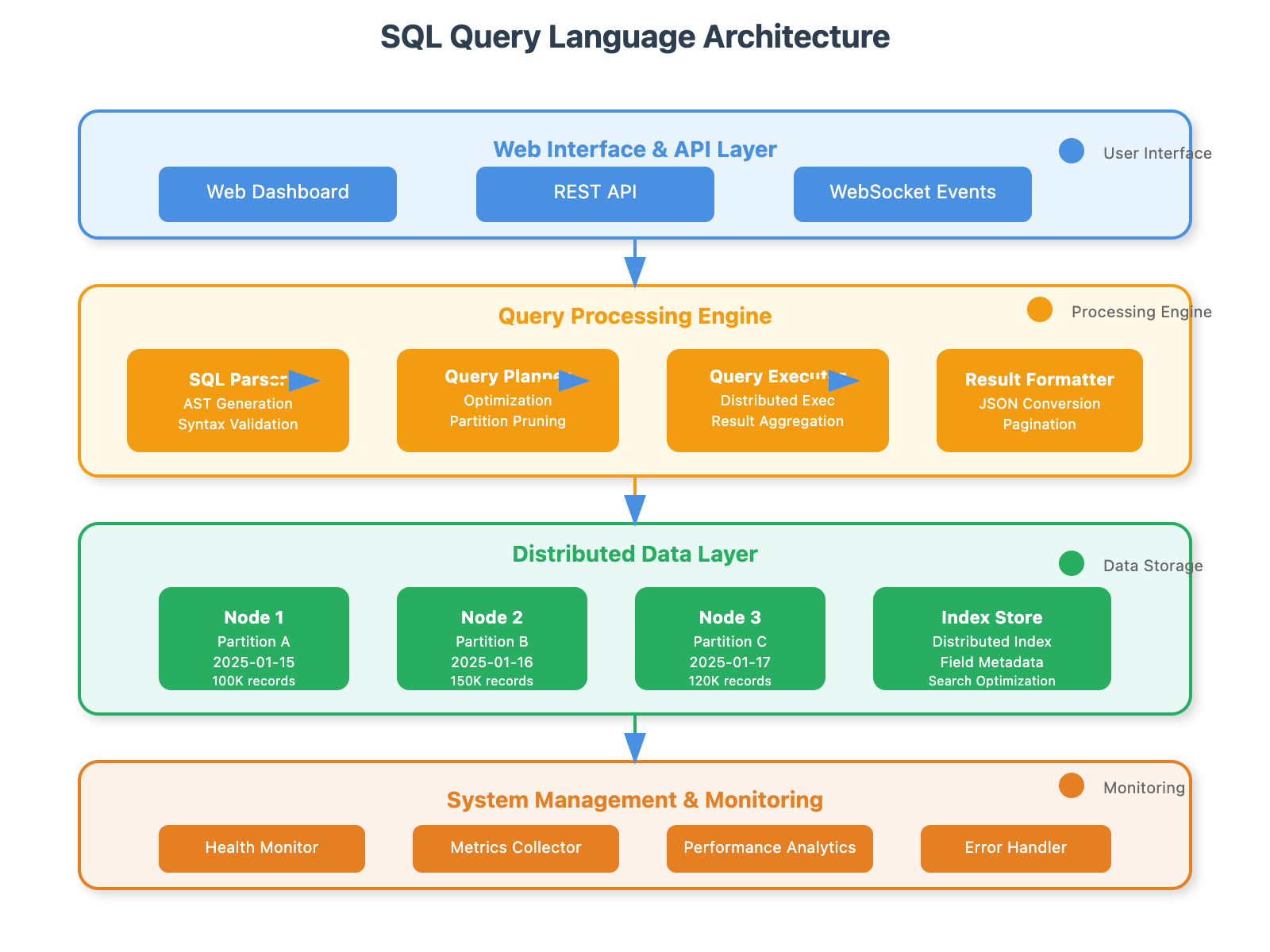
SQL Parser Architecture: Transform text queries into processable Abstract Syntax Trees
Distributed Query Planning: Implement partition pruning and predicate pushdown optimizations
Coordinated Execution: Manage parallel operations across multiple nodes with fault tolerance
Performance Optimization: Apply the same techniques used by major database systems
Production Integration: Build web interfaces and monitoring for real-world deployment
Think of today's lesson as building the "Google search" for your distributed log data. Users ask questions in familiar SQL syntax, and your system intelligently routes those questions to find answers across millions of log entries in milliseconds.
The Challenge: Making Distributed Search Feel Simple
When Netflix engineers need to debug a service outage, they don't want to think about which of their 500 servers might have relevant logs. They want to ask: "Show me all errors from the recommendation service in the last hour that mention user authentication." Your query language makes this possible by abstracting away distributed system complexity while leveraging the partitioned indexes you built on Day 53.
[📊 : Component Architecture Diagram]