Day 49: Implement Anomaly Detection Algorithms for Distributed Log Processing
What We’re Building Today
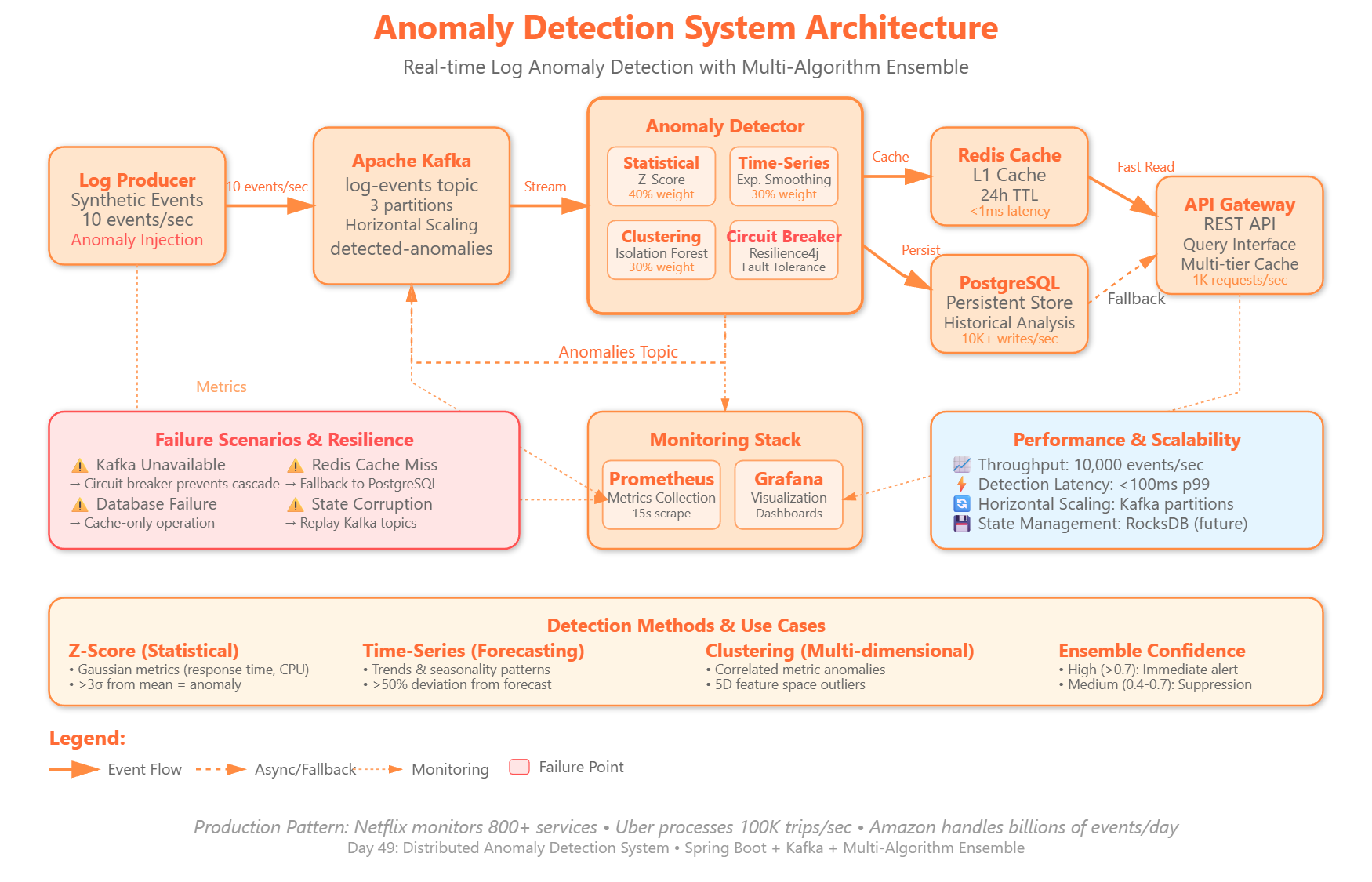
Today we’re implementing a production-grade anomaly detection system that processes streaming log data to identify unusual patterns in real-time. You’ll build:
Statistical anomaly detection engine using Z-score and IQR methods for numeric metrics
Time-series pattern recognition detecting deviations from historical baselines
Multi-dimensional clustering identifying outliers across correlated log attributes
Adaptive threshold system that learns normal behavior and adjusts detection sensitivity
Real-time alerting pipeline with confidence scoring and false-positive suppression
Why This Matters: Production Anomaly Detection at Scale
Anomaly detection is critical infrastructure at companies processing billions of events daily. Netflix’s anomaly detection system monitors 800+ microservices, detecting issues before they impact customer experience. Uber’s real-time fraud detection processes 100,000 trip events per second, identifying suspicious patterns within milliseconds. Amazon’s operational intelligence systems scan millions of metrics to prevent outages.
The challenge isn’t just detecting anomalies—it’s doing so with minimal false positives while maintaining sub-second latency at massive scale. Traditional threshold-based alerting breaks down when you have thousands of metrics with dynamic baselines. Statistical methods provide precision, but require careful tuning for seasonality, trends, and multi-modal distributions.
Today’s implementation demonstrates how to build adaptive anomaly detection that scales horizontally, maintains accuracy under load, and integrates with existing observability infrastructure. The patterns you’ll implement power the monitoring systems behind modern distributed platforms.
System Design Deep Dive