Day 43: Implement Log Compaction for State Management
What We’re Building Today
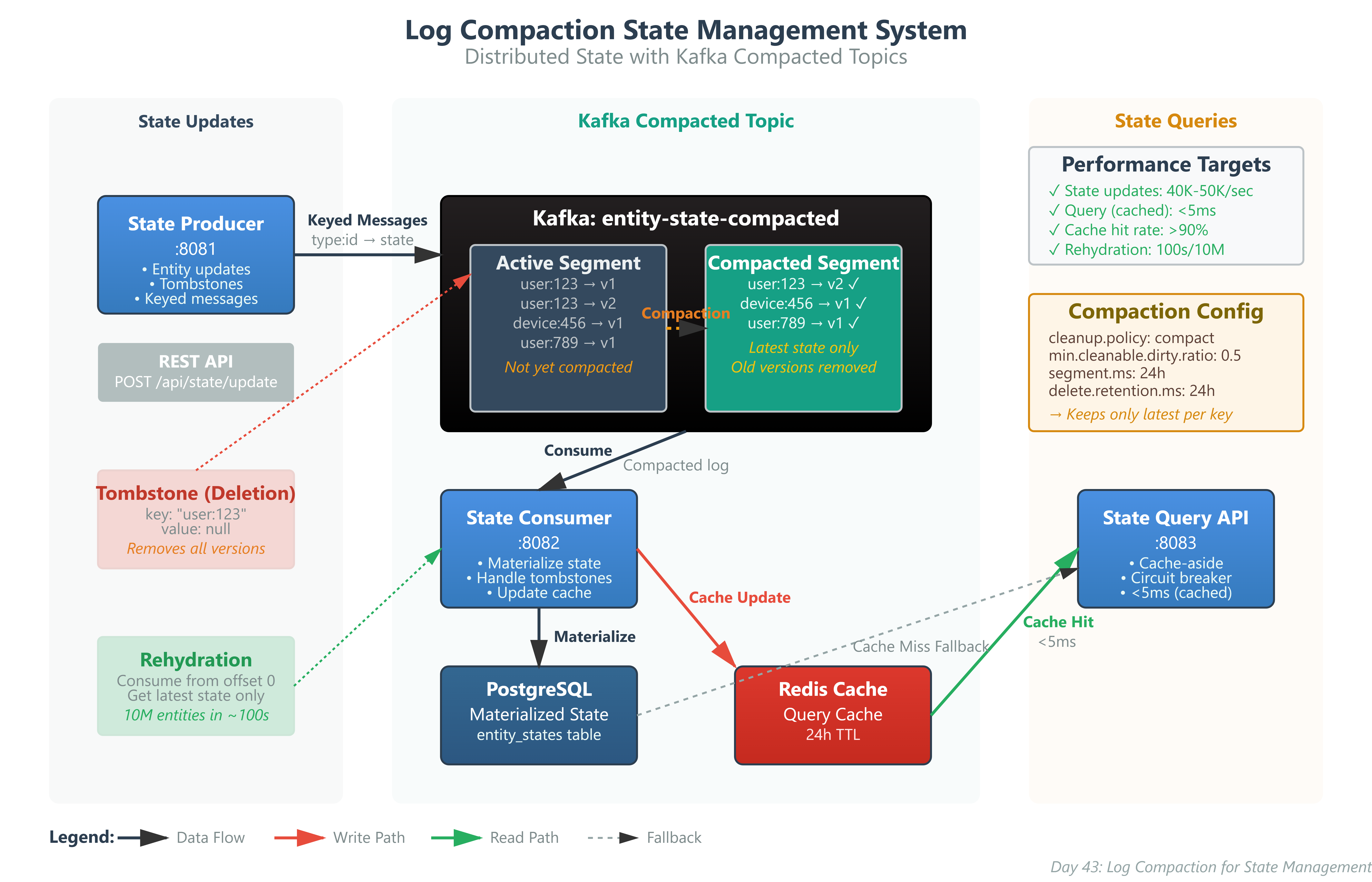
Today we’re implementing a production-grade state management system using Kafka log compaction:
Compacted Topics that maintain only the latest state for each entity key
State Producer Service generating entity lifecycle events with proper keying
State Consumer Service maintaining current entity snapshots from the compacted log
State Query API providing fast lookups of current entity state with Redis caching
Why This Matters: The State Management Challenge at Scale
Every distributed system faces the same fundamental challenge: how do you maintain current state across dozens of microservices without creating a monolithic database bottleneck?
Traditional approaches fail at scale. Storing complete event histories consumes unbounded storage. Database-per-service patterns create consistency nightmares during failures. Cache invalidation becomes impossibly complex with hundreds of service instances.
Log compaction solves this by treating your event log as a self-maintaining state store. Instead of storing every state transition, Kafka automatically retains only the latest value for each key. This gives you the benefits of event sourcing (complete audit trail, replayability, temporal queries) while maintaining bounded storage and fast state reconstruction.
Netflix uses this pattern to maintain current device registration state across 200+ million subscribers. When a device registers, deregisters, or updates settings, those events flow through compacted topics. Any service can rebuild complete device state by consuming from offset 0, getting only current registrations. Uber applies the same pattern to driver location state, maintaining billions of location updates while keeping storage constant.