Day 42: Exactly-Once Processing Semantics in Distributed Log Systems
What We’re Building Today
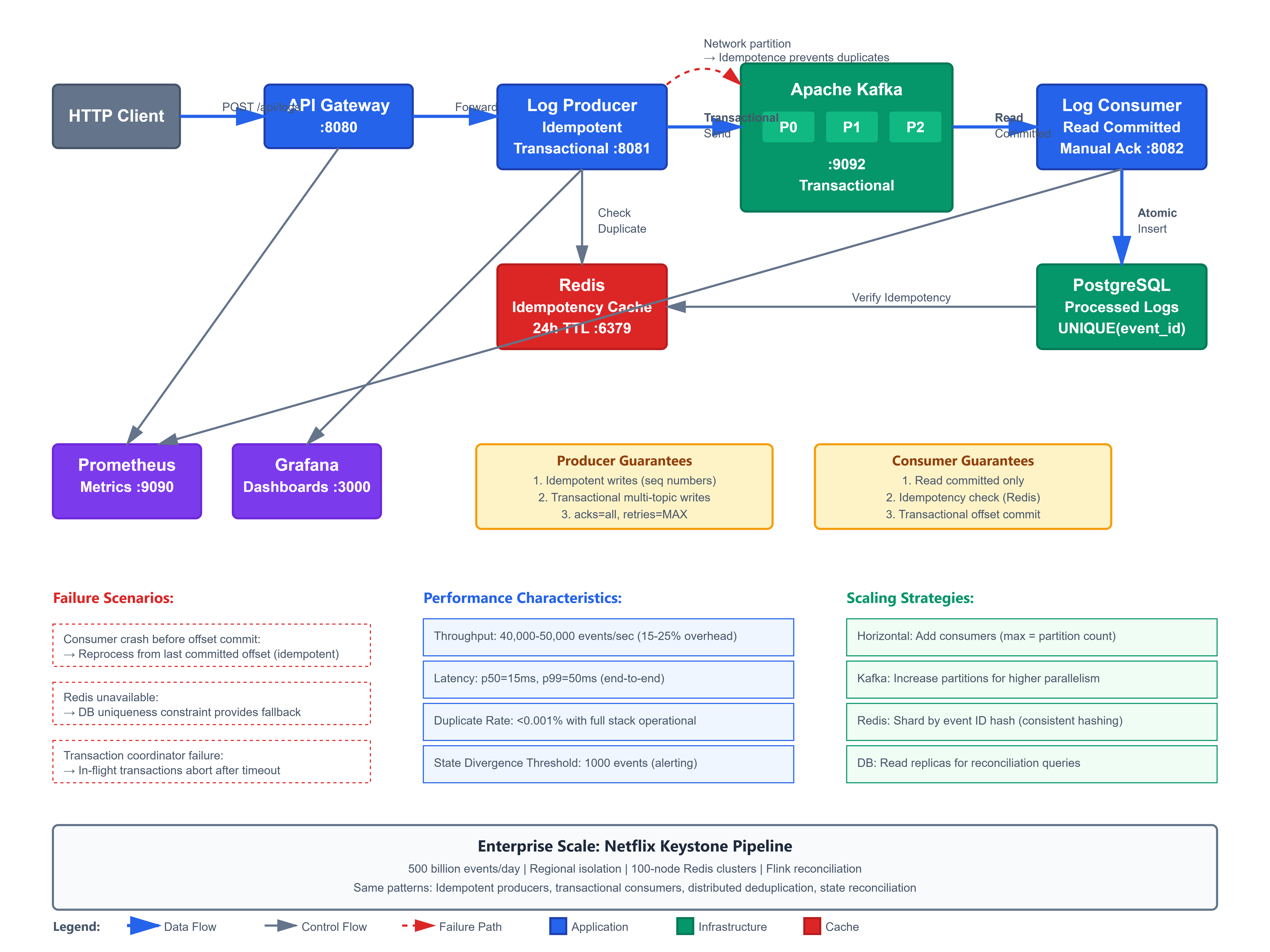
Today we implement exactly-once processing semantics in our Kafka-based log processing system, guaranteeing no duplicate message processing even during failures:
Idempotent Kafka producers preventing duplicate writes on network retries
Transactional message processing with atomic offset commits and database writes
Deduplication layer using Redis for distributed idempotency keys
State reconciliation service detecting and recovering from processing anomalies
End-to-end exactly-once pipeline from producer through consumer to database
Why This Matters: The $10 Million Double-Charge Problem
In 2019, a major payment processor experienced a 47-second network partition during peak Black Friday traffic. Their Kafka consumers lost connections, reconnected, and reprocessed 180,000 payment authorization messages—charging customers twice. The cost: $10.3 million in refunds, regulatory fines, and customer service overhead.
The root cause wasn’t Kafka. It was the absence of exactly-once semantics. Without idempotent producers, network retries created duplicate messages. Without transactional consumers, offset commits happened before database writes, causing reprocessing on crashes. Without deduplication, the same payment ID was processed multiple times.
Exactly-once processing isn’t about theoretical correctness—it’s about financial accuracy, compliance requirements, and system reliability at scale. When Uber processes 100 million trip events daily, Stripe handles billions in transactions, or AWS Lambda processes trillions of invocations, “at-least-once with deduplication” becomes a critical architectural pattern.