

Day 40: Building Kafka Consumers for Real-Time Log Processing
The Engine That Powers Netflix's Real-Time Analytics

254-Day Hands-On System Design Series
Module 2: Scalable Log Processing | Week 6: Stream Processing with Kafka
Welcome back to our distributed systems journey!
Think about Netflix processing 8 billion hours of content watched monthly. Every play, pause, skip, and rewind generates logs that must be processed instantly to update recommendations, detect playback issues, and optimize content delivery. The secret? Kafka consumers working tirelessly to transform raw log streams into actionable insights.
Yesterday you built producers that efficiently shipped logs to Kafka topics. Today we're constructing the other half - intelligent consumers that can process millions of log entries per second while maintaining exactly-once semantics and fault tolerance.
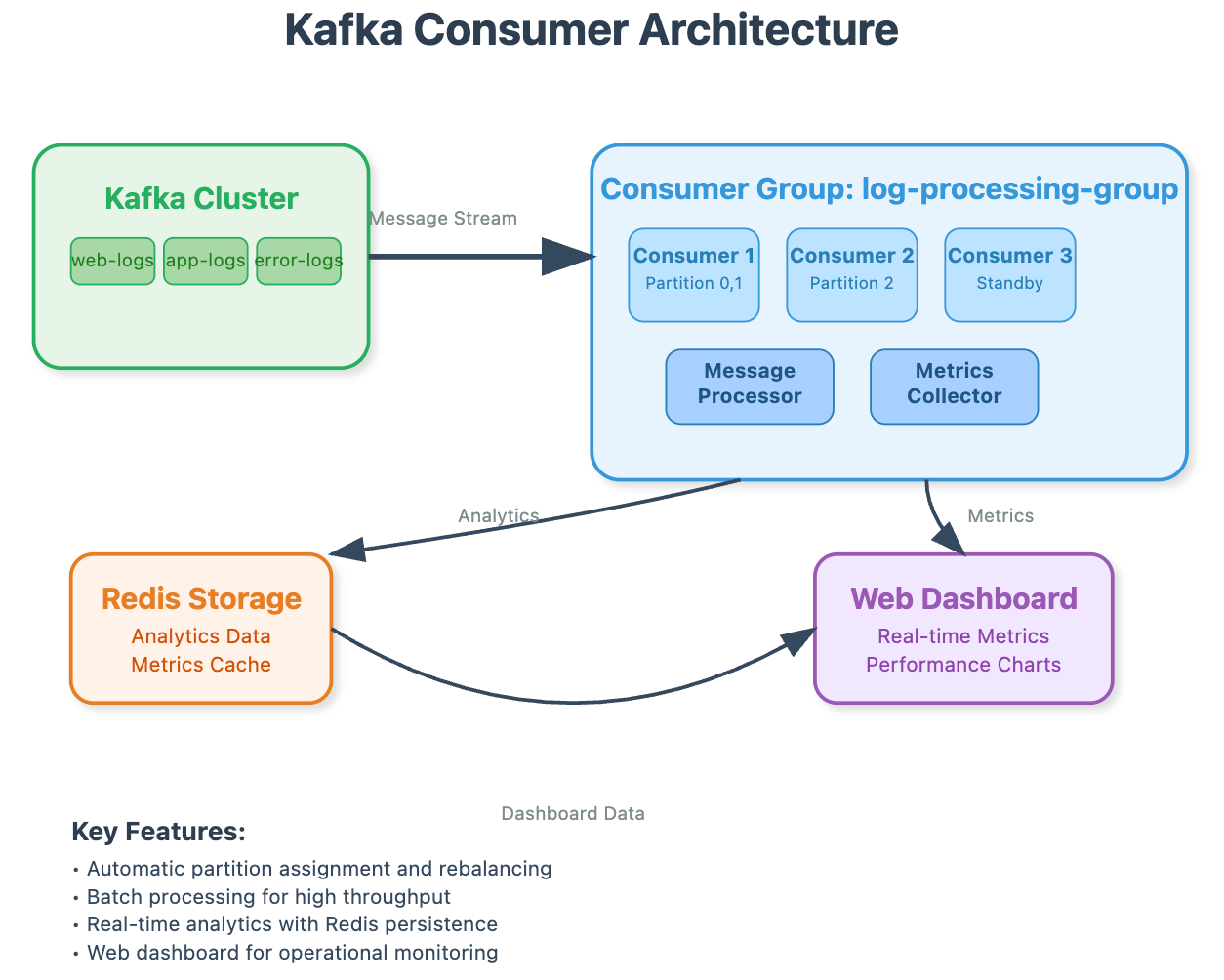
The Consumer Revolution
Traditional log processing systems use pull-based polling: "Check if new logs exist, process them, repeat." This creates inefficient busy-waiting and introduces processing delays. Kafka consumers revolutionize this with smart group coordination and offset management.
Here's what makes Kafka consumers special: they don't just read messages, they coordinate among themselves to ensure parallel processing without duplication. When Consumer A fails, Consumer B automatically picks up the workload. When traffic spikes, new consumers join seamlessly.
[📊 Image: Component Architecture Diagram]