Day 33: Implement Consumers to Process Logs from Queues
What We’re Building Today
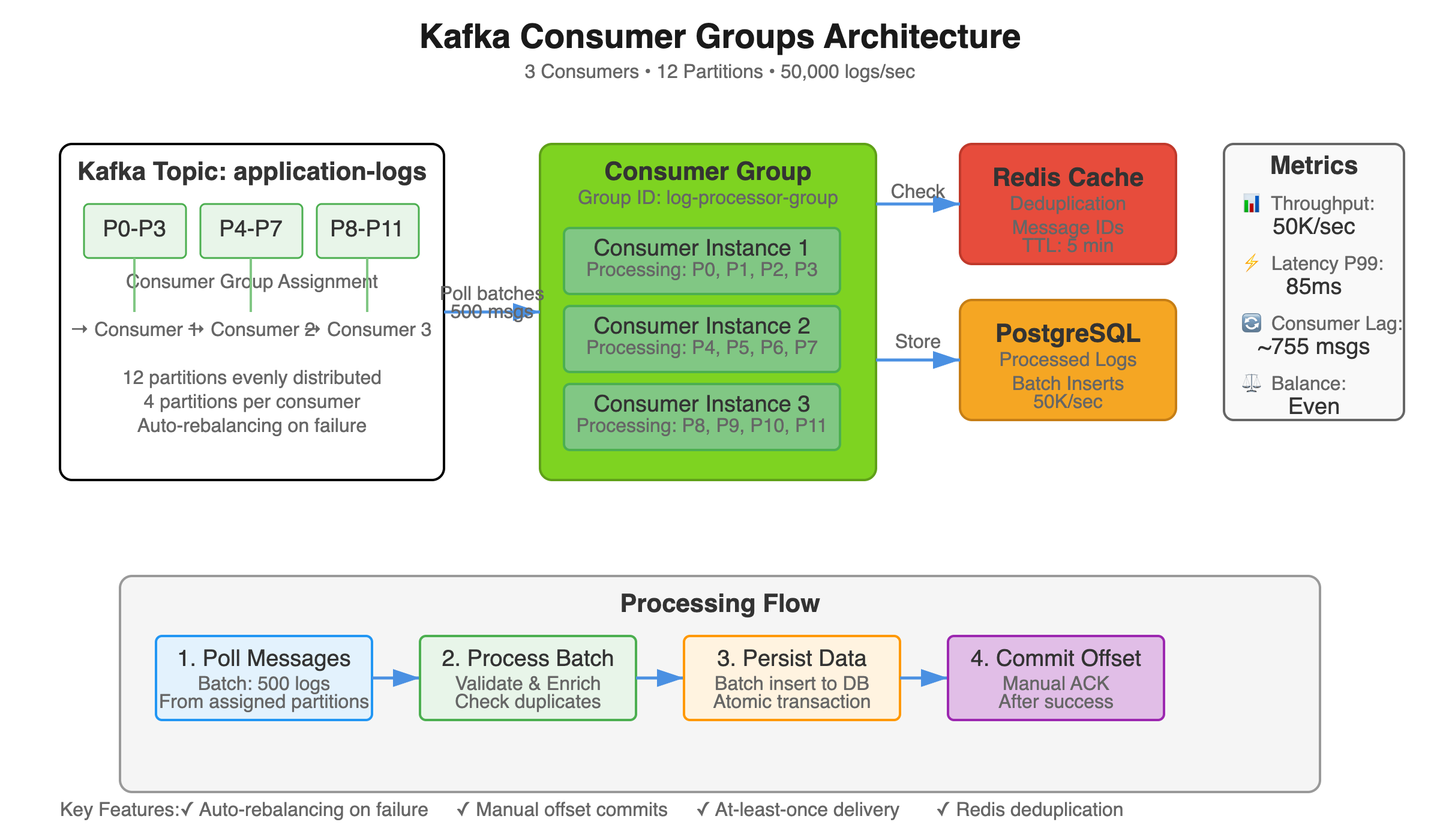
Consumer group architecture with automatic partition rebalancing across multiple instances
Parallel log processing pipeline handling 50,000+ events/second with sub-100ms P99 latency
Offset management strategies for reliable message consumption and failure recovery
Backpressure-aware processing with dynamic batch sizing and flow control mechanisms
Why This Matters: The Consumer Scalability Challenge
While producers must handle bursts of incoming events, consumers face a different scaling challenge: processing throughput must match or exceed production rate to prevent unbounded queue growth. At Uber, their logging infrastructure processes 100 billion events daily across thousands of consumer instances. When a deployment temporarily doubles processing latency from 50ms to 100ms, consumer lag can balloon to hours of backlog within minutes, causing cascading failures in dependent systems that rely on near-real-time log insights.
The consumer side introduces unique distributed systems challenges that don’t exist for producers. Consumer groups must dynamically rebalance partition assignments as instances fail or scale, requiring consensus protocols that temporarily pause all consumption. Netflix’s consumer infrastructure restarts ~10,000 instances daily across their fleet, triggering ~500 rebalance operations per minute during peak deployment windows. Poor rebalancing strategies can create 30-60 second processing gaps, causing violations of their 99.9% SLA for anomaly detection pipelines that power their recommendation engine.