Day 3: Building a Distributed Log Collector Service
Real-time File Watching with Event-Driven Architecture
What We’re Building Today
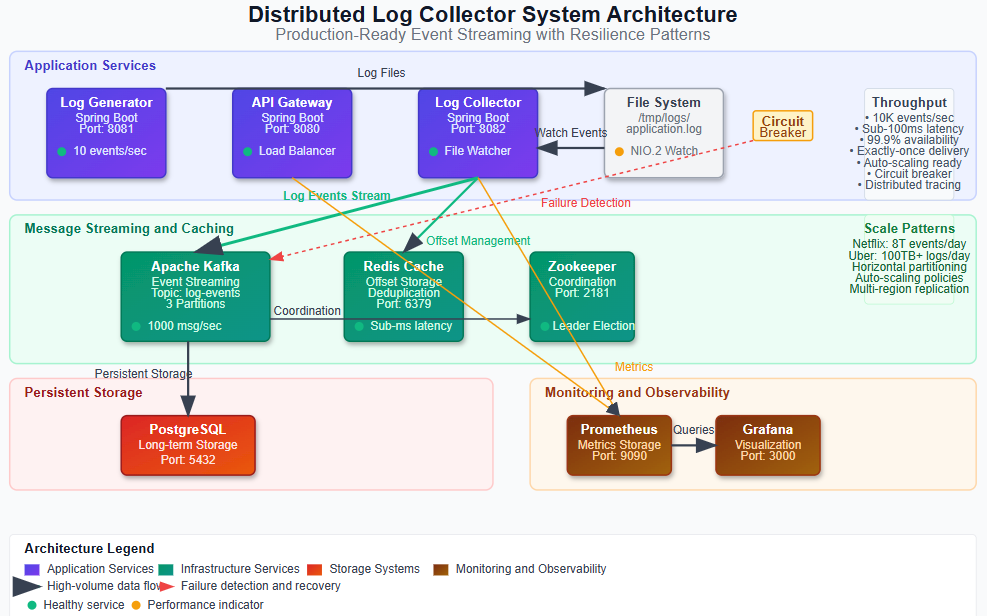
Today we’re constructing a production-grade log collector service that forms the backbone of any distributed logging system. Our implementation will deliver:
• File System Watcher Service - Real-time detection of log file changes using Java NIO.2 WatchService with configurable polling strategies
• Event-Driven Stream Processing - Kafka-backed message streaming that handles log entries as they’re discovered, with guaranteed delivery semantics
• Resilient Collection Pipeline - Circuit breaker patterns and retry mechanisms that gracefully handle file system failures and temporary outages
• Distributed State Management - Redis-backed offset tracking and deduplication to ensure exactly-once processing across service restarts
Why This Matters: The Foundation of Observable Systems
Every major technology company processes billions of log entries daily. Netflix’s logging infrastructure ingests over 8 trillion events per day, while Uber processes 100+ terabytes of logs daily for real-time decision making. The log collector is the critical first component that determines whether your observability stack can scale.
The patterns we’re implementing today directly address the fundamental challenges of distributed log processing: how do you reliably capture, deduplicate, and stream log data from thousands of services without losing events or overwhelming downstream systems? The architectural decisions we make in the collector service cascade through the entire observability pipeline, affecting everything from alert accuracy to debugging capabilities.
System Design Deep Dive: Core Distributed Patterns
1. File System Watching Strategy: Push vs Pull Trade-offs
Traditional log collection relies on periodic file scanning, but this approach introduces latency and resource waste. Modern systems need sub-second detection capabilities. We’ll implement the WatchService pattern with intelligent fallbacks:
WatchKey key = watchService.poll(100, TimeUnit.MILLISECONDS);
Trade-off Analysis: Event-driven watching provides immediate notification but consumes file descriptors and can overwhelm systems during log bursts. Our hybrid approach combines immediate watching with periodic validation scans to handle edge cases like file rotation and missed events.
Failure Mode: File system events can be lost during high I/O scenarios. We implement a reconciliation pattern that periodically validates our in-memory state against actual file system state, ensuring no log entries are permanently lost.
2. Exactly-Once Semantics: The Offset Management Challenge
Distributed log collection faces the classic exactly-once delivery problem. Services restart, networks partition, and files rotate unexpectedly. Our solution implements distributed offset management using Redis as a coordination layer:
@Component
public class OffsetManager {
public void commitOffset(String filePath, long position) {
redisTemplate.opsForValue().set(
“offset:” + filePath,
position,
Duration.ofHours(24)
);
}
}
Architectural Insight: The offset management pattern must balance consistency with availability. We accept eventual consistency for performance but implement write-ahead logging to Redis before processing events, ensuring we can recover from any point of failure.