Day 22: Multi-Node Storage Cluster with File Replication
What We’re Building Today
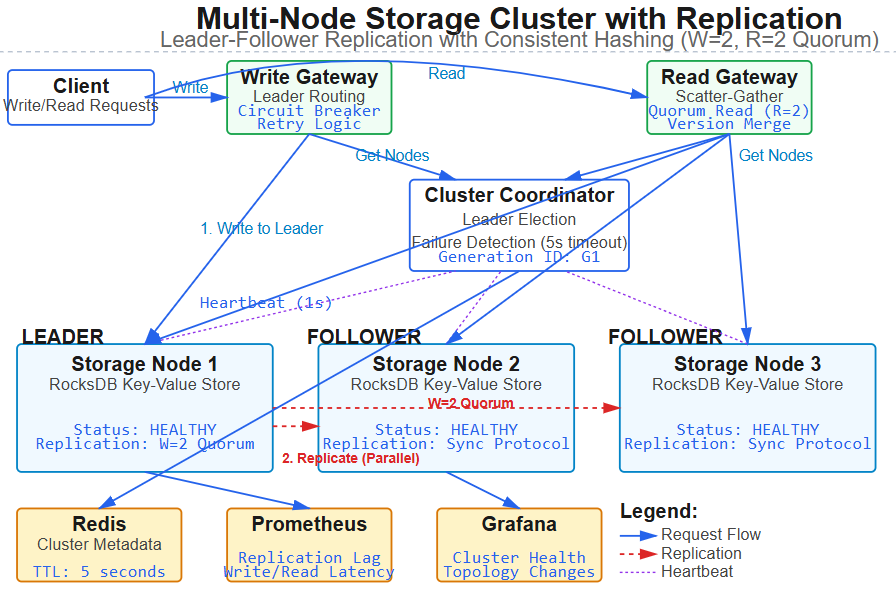
Today we implement a distributed storage cluster that replicates log data across multiple nodes, introducing core distributed systems patterns:
Three-node storage cluster with leader election and automatic failover
Synchronous replication protocol ensuring data durability across node failures
Consistent hashing ring for intelligent data distribution and rebalancing
Health monitoring system with automatic node recovery and partition handling
Why This Matters: From Single Point of Failure to Distributed Resilience
Every production system eventually faces the question: what happens when your storage node dies at 3 AM? Single-node storage represents the most critical failure point in any log processing pipeline. When that node fails, you lose data, visibility, and the ability to diagnose ongoing incidents.
Netflix processes over 500 billion log events daily across thousands of microservices. A single storage node failure would be catastrophic—losing visibility into which services are degraded, making incident response impossible. Their solution? A distributed storage cluster where each log exists on multiple nodes, and any single node failure is transparent to the system.
The replication pattern we’re building today forms the foundation of every distributed database, from Cassandra to MongoDB to Elasticsearch. Understanding replication at this fundamental level—handling network partitions, consistency guarantees, and failure detection—prepares you to architect systems that survive real-world chaos.