

Day 18: Building a Log Format Normalization Service
What We’re Building Today
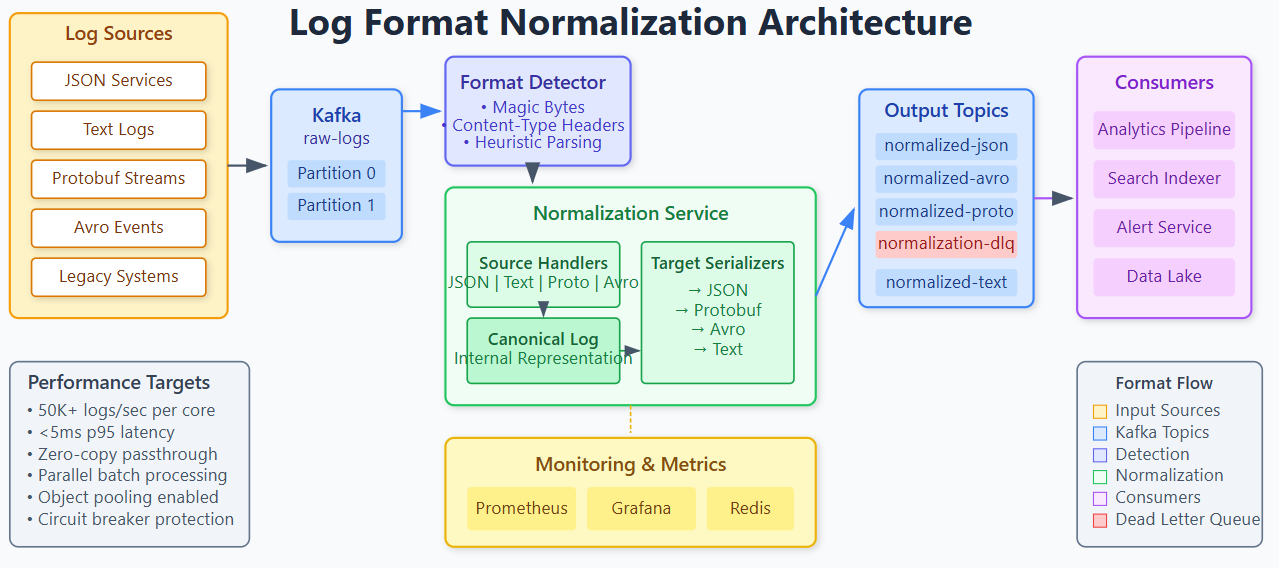
Today you’ll implement a production-grade log normalization service that transforms logs between different serialization formats. By the end of this lesson, you’ll have:
A format detection engine that identifies incoming log formats automatically
Bidirectional converters between text, JSON, Protocol Buffers, and Avro
A transformation pipeline with pluggable format handlers
Performance-optimized batch processing for high-throughput normalization
Comprehensive metrics tracking conversion rates and format distributions
Why Format Normalization Matters
In real distributed systems, logs arrive in whatever format their source systems prefer. Your Java microservices emit JSON. That legacy COBOL batch job writes fixed-width text. The IoT sensors stream Protocol Buffers. The data science team needs everything in Avro for their Spark pipelines.
Without normalization, you face two bad options: force all producers to adopt a single format (politically impossible and technically disruptive), or build custom integrations for every producer-consumer pair (N×M complexity explosion). A normalization service gives you a third option: let producers emit their native format and transform at ingestion time.
Netflix processes over 500 billion events daily from thousands of different services. Their data pipeline normalizes everything into a canonical format before storage, enabling consistent querying regardless of source. Uber’s logging infrastructure handles similar diversity—mobile clients, server-side services, and embedded systems all speaking different serialization dialects.
The architectural insight here is that format normalization is a form of decoupling. Just as message queues decouple producers from consumers in time, format normalization decouples them in representation. This decoupling enables independent evolution—your analytics team can switch from JSON to Avro without coordinating with every upstream producer.
System Design Deep Dive
Format Detection Strategy
The first challenge is identifying what format an incoming log entry uses. You have three approaches:
Content-Type Headers: If logs arrive via HTTP or Kafka with metadata, trust the declared content type. This is fastest but assumes producers are honest.
Magic Bytes: Binary formats like Avro and Protobuf have identifiable byte sequences. Avro files start with Obj1, Protocol Buffers have characteristic field tag patterns. This works for binary formats but fails for text versus JSON.
Heuristic Parsing: Try parsing as JSON first (look for opening brace), fall back to structured text patterns, default to raw text. This is slowest but most robust.
Production systems typically use a tiered approach: trust headers when present, fall back to magic bytes for binary, use heuristics for text-based formats. The key trade-off is speed versus accuracy—aggressive caching of detection results helps.
Transformation Pipeline Architecture
Design your pipeline as a series of composable stages:
Input → Detection → Parsing → Canonical Form → Serialization → OutputThe canonical form is critical. Rather than building O(N²) direct converters between every format pair, convert everything to an internal representation first. This gives you O(N) complexity—one parser and one serializer per format.
Your canonical form should preserve all information. Use a structure like:
Timestamp (normalized to UTC microseconds)
Severity level (mapped to standard enum)
Source metadata (service, host, trace ID)
Structured fields (key-value map)
Raw message (original text if applicable)
This approach has a cost: double serialization overhead. For high-throughput systems, consider direct conversion paths for common format pairs (JSON→Avro is probably 80% of your traffic) while keeping the canonical path as fallback.
Schema Mapping Challenges
Converting between formats isn’t just about syntax—it’s about semantics. Consider these mapping challenges:
Type Coercion: JSON numbers have no integer/float distinction. Protobuf has int32, int64, float, double. When converting JSON to Protobuf, you need schema hints or heuristics (decimal point means float, large values need int64).
Null Handling: JSON has explicit null. Protobuf uses default values (empty string, zero). Avro has union types for nullable fields. Your normalizer must track whether a field was explicitly null versus absent versus default.
Nested Structures: JSON allows arbitrary nesting. Protobuf requires predefined message types. When normalizing dynamic JSON to Protobuf, you either flatten the structure or use a generic Struct type (losing type safety).
Array Types: Avro arrays are homogeneous. JSON arrays can mix types. Your normalizer must either reject heterogeneous arrays or use union types.
The production-grade solution is maintaining format-specific schemas that define these mappings explicitly. Tomorrow’s schema registry lesson will show how to manage these schemas centrally.
Performance Optimization
Format conversion is CPU-bound work. Optimize with these techniques:
Object Pooling: Reuse parser and serializer instances. Creating a new Jackson ObjectMapper per request is expensive.
Buffer Management: Pre-allocate byte buffers for serialization output. Size them based on average message size plus headroom.
Batch Processing: Convert multiple logs per pipeline invocation. This amortizes the cost of schema lookups and object allocation.
Parallel Conversion: Partition incoming logs by format type and process partitions in parallel. Each format uses different code paths, so there’s no contention.
Zero-Copy Where Possible: If source and destination use the same format, pass through without parsing. This sounds obvious but is often overlooked.
Benchmarks show that naive conversion handles about 5,000 logs/second per core. With these optimizations, you can reach 50,000+/second. The bottleneck shifts from CPU to memory bandwidth at that point.
Implementation Walkthrough
Github Link:
https://github.com/sysdr/sdc-java/tree/main/day18/log-normalization-systemThe implementation centers on a FormatNormalizer service with pluggable handlers:
public class FormatNormalizer {
private final Map<LogFormat, FormatHandler> handlers;
private final FormatDetector detector;
public NormalizedLog normalize(byte[] input, LogFormat targetFormat) {
LogFormat sourceFormat = detector.detect(input);
FormatHandler sourceHandler = handlers.get(sourceFormat);
FormatHandler targetHandler = handlers.get(targetFormat);
CanonicalLog canonical = sourceHandler.parse(input);
return targetHandler.serialize(canonical);
}
}
Each FormatHandler implements parsing and serialization for one format. The JsonFormatHandler uses Jackson, ProtobufFormatHandler uses the generated message classes from Day 16, and AvroFormatHandler uses the schema-aware serializer from Day 17.
The FormatDetector runs through detection strategies in order:
public LogFormat detect(byte[] input) {
// Check for Avro magic bytes
if (input.length >= 4 && input[0] == ‘O’ && input[1] == ‘b’
&& input[2] == ‘j’ && input[3] == 1) {
return LogFormat.AVRO;
}
// Check for JSON structure
if (input[0] == ‘{’ || input[0] == ‘[’) {
return LogFormat.JSON;
}
// Protobuf detection via field tag pattern
if (isValidProtobuf(input)) {
return LogFormat.PROTOBUF;
}
return LogFormat.TEXT;
}
The batch processing endpoint accepts multiple logs and returns results with per-log status:
@PostMapping(”/normalize/batch”)
public BatchResult normalizeBatch(@RequestBody BatchRequest request) {
return request.getLogs().parallelStream()
.map(log -> normalize(log, request.getTargetFormat()))
.collect(toBatchResult());
}
Error handling is crucial. When a log fails to parse, you have options: skip it (loses data), send to dead letter queue (defers the problem), or include raw bytes in output with error flag (preserves data but complicates consumers). The implementation uses the third approach with configurable fallback behavior.
Working Code Demo:
Production Considerations
Monitoring Format Distribution
Track which formats you’re receiving and converting to. Metrics to capture:
normalization_requests_totalby source_format, target_format, statusnormalization_duration_secondshistogram by format pairdetection_accuracy(when headers are present, does detection match?)conversion_errors_totalby error_type (parse_failure, schema_mismatch, unknown_format)
These metrics reveal operational insights. A sudden spike in TEXT format might indicate a misconfigured producer. Increasing conversion errors for JSON→Protobuf suggests schema drift.
Failure Scenarios
Schema Evolution Mismatch: Source adds a field that target schema doesn’t expect. Solution: configure unknown field handling (ignore, error, or forward as metadata).
Memory Pressure: Large log batches exhaust heap. Solution: streaming parsers that process incrementally, backpressure on batch size.
Format Detection Failures: Corrupted input misidentified. Solution: validation after parsing, checksum verification for binary formats.
Deployment Topology
Deploy normalizers as a stateless service behind a load balancer. Scale horizontally based on CPU utilization. Keep normalizers close to Kafka brokers to minimize network latency on high-volume paths.
Scale Connection
At FAANG scale, format normalization becomes a dedicated infrastructure service. LinkedIn’s data pipeline normalizes over 2 trillion messages daily through their “Gobblin” ingestion framework. They optimize for specific format pairs and maintain format-specific clusters.
Google’s protocol buffer ecosystem includes protoc plugins that generate format converters automatically. Their internal logging infrastructure converts everything to a canonical protobuf format optimized for their Dremel query engine.
The pattern you’re implementing today—canonical intermediate representation with pluggable handlers—is exactly how these systems work. The difference is scale (millions vs. trillions) and optimization depth (generic vs. format-pair-specific fast paths).
Next Steps
Tomorrow we’ll build a schema registry service that centralizes format definitions and validates compatibility. This solves the schema mapping challenges we encountered today—instead of hardcoding type mappings, we’ll look them up dynamically. The registry also enables schema evolution without breaking existing consumers, a critical capability for production systems.