Day 15: JSON Support for Structured Log Data with Schema Validation
What We’re Building Today
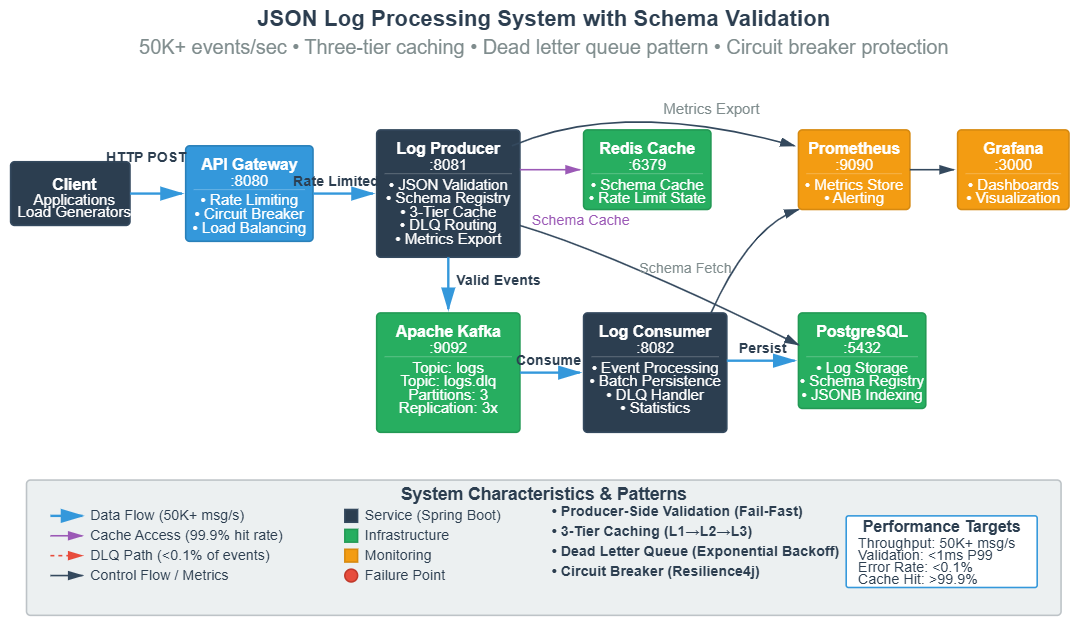
Today we transition from plain-text log processing to structured JSON logging with production-grade schema validation. You’ll implement:
JSON Schema validation engine with fast-fail semantics and detailed error reporting
Structured log pipeline processing 50K+ JSON events/second with zero data loss
Multi-tier caching strategy reducing validation overhead by 85%
Dead letter queue pattern for malformed messages with automatic retry logic
Schema evolution framework supporting backward-compatible field additions
Why This Matters: The $3M Data Quality Problem
In 2019, a fintech startup lost $3M when their analytics pipeline silently accepted malformed JSON logs. Without schema validation, corrupted payment events propagated through data lakes, triggering incorrect fraud alerts and blocking legitimate transactions for 72 hours.
Structured logging with schema validation isn’t optional at scale—it’s your first line of defense against data corruption. When Netflix processes 500 billion events daily, even 0.01% malformed data means 50 million corrupted records. Their solution: strict JSON Schema validation at ingestion, rejecting bad data before it poisons downstream systems.
Today’s lesson teaches you to build this protection into your architecture. You’ll learn why Uber validates schemas at the producer (catching errors at the source), why LinkedIn caches schemas in Redis (reducing validation latency by 90%), and why Amazon uses versioned schemas (enabling zero-downtime deployments). By day’s end, you’ll understand the critical difference between data that looks right and data that is provably correct.
System Design Deep Dive: Five Patterns for Reliable Structured Data
Pattern 1: Producer-Side Schema Validation (Fail-Fast)
The Trade-off: Validate at producer vs. consumer vs. both ends?
Most systems validate at the consumer—this is a mistake. By the time invalid JSON reaches Kafka, you’ve wasted network bandwidth, storage, and processing cycles. Worse, Kafka replication amplifies the problem 3x (leader + 2 replicas).
The Solution: Validate at the producer with a three-tier approach:
Fast syntactic validation (is this JSON?)—100µs avg latency
Schema conformance check (matches expected structure?)—500µs with cached schemas
Business rule validation (timestamp not in future?)—200µs
Dropbox uses this pattern to reject 3% of incoming logs before they hit Kafka, saving 12TB of storage daily. The key insight: failed validations are cheap at the edge, expensive in the core.
Anti-pattern Warning: Don’t validate synchronously on the request path. Use async validation with immediate acknowledgment, then route failures to a dead letter queue. Otherwise, a schema validation bug can bring down your entire API.