Day 149: Orchestrating Your Log Processing Empire with Kubernetes
What You’re Building Today
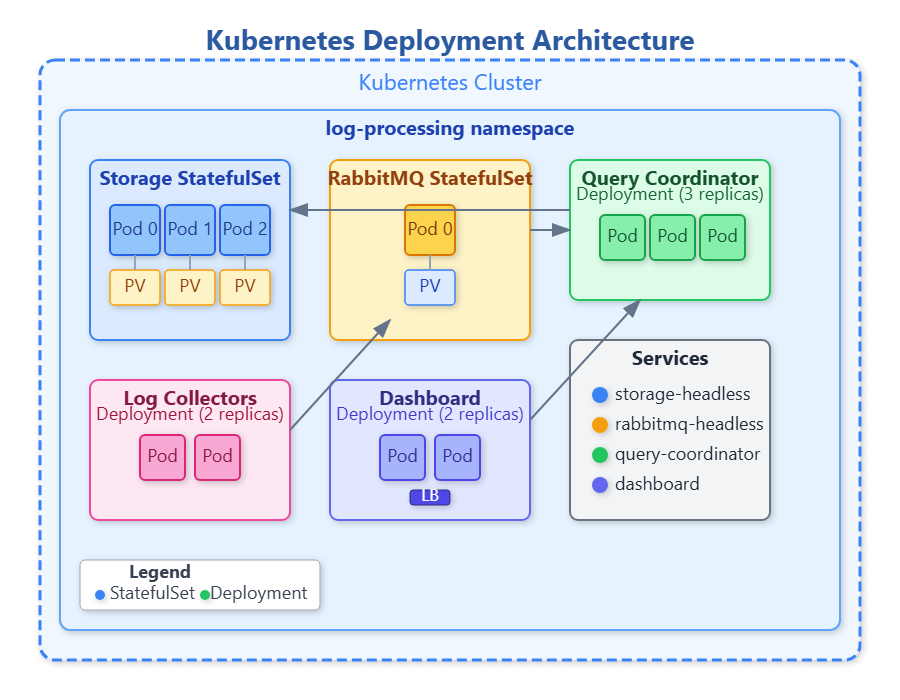
You’ve spent months constructing a sophisticated distributed log processing system—collectors ingesting data, RabbitMQ routing messages, query engines processing natural language requests, storage clusters maintaining consistency. Today, you’ll learn to deploy this entire ecosystem using Kubernetes, transforming your collection of services into a resilient, self-healing production platform.
By day’s end, you’ll have complete Kubernetes manifests that can deploy your log processing system to any Kubernetes cluster with a single command, handling failures gracefully and scaling components independently based on load.
The Container Orchestration Reality
Running distributed systems in production means managing dozens of interconnected services across multiple machines. Airbnb runs over 1,000 microservices on Kubernetes. Spotify serves 400+ million users through containerized workloads. These companies don’t manually SSH into servers to start processes—they declare their desired state, and Kubernetes makes it happen.
Without orchestration, deploying your log processing system requires manually starting processes on different servers, configuring networking, monitoring health, and restarting failed components. One crashed server means manual intervention. Kubernetes automates all of this, treating your entire system as declarative configuration.