

Day 116: Implement Data Restoration from Archives
Today’s Mission: Building Your Log Time Machine
Today we’re implementing the retrieval half of your archiving system - the ability to seamlessly query historical logs stored in archives. Think of Netflix’s viewing history feature: users can search years of data instantly, even though most of it lives in cold storage.
What You’ll Build:
Archive query router that automatically detects historical queries
Streaming decompression engine for large archive files
Smart caching layer for frequently accessed archives
Unified API that combines live and archived data seamlessly
The Archive Retrieval Challenge
When Spotify analyzes user listening patterns over 2+ years, they’re querying petabytes of archived data. The challenge isn’t just storage - it’s making archived data feel as accessible as live data while managing costs and performance.
Most systems fail here because they treat archived data as a separate concern, forcing users to know whether their query hits live or historical data. Production systems hide this complexity entirely.
Core Architecture Components
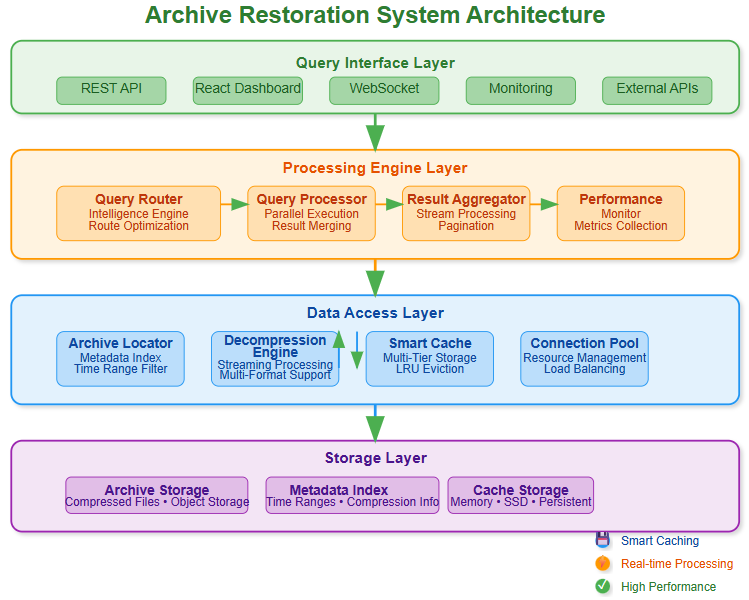
Query Intelligence Router
The router analyzes incoming queries to determine the optimal data sources. A query for “errors in the last hour” hits live data, while “monthly error trends” triggers archive retrieval. Smart routing prevents unnecessary archive access.
Archive Locator Service
Maps time ranges to specific archive files across storage tiers. Uses metadata indexes to quickly identify relevant archives without scanning entire storage systems. Critical for sub-second query response times.
Streaming Decompression Engine
Processes compressed archives in chunks rather than loading entire files into memory. Supports multiple compression formats (gzip, lz4, zstd) and can decompress while searching, reducing I/O overhead.
Result Merger
Combines data from multiple sources (live streams, recent archives, cold storage) into unified result sets. Handles deduplication, sorting, and pagination across heterogeneous data sources.
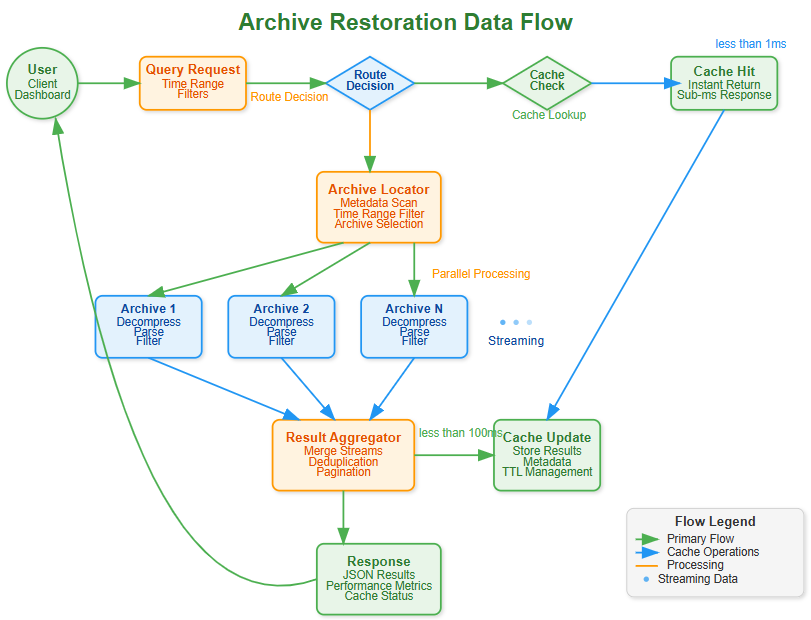
Implementation Flow
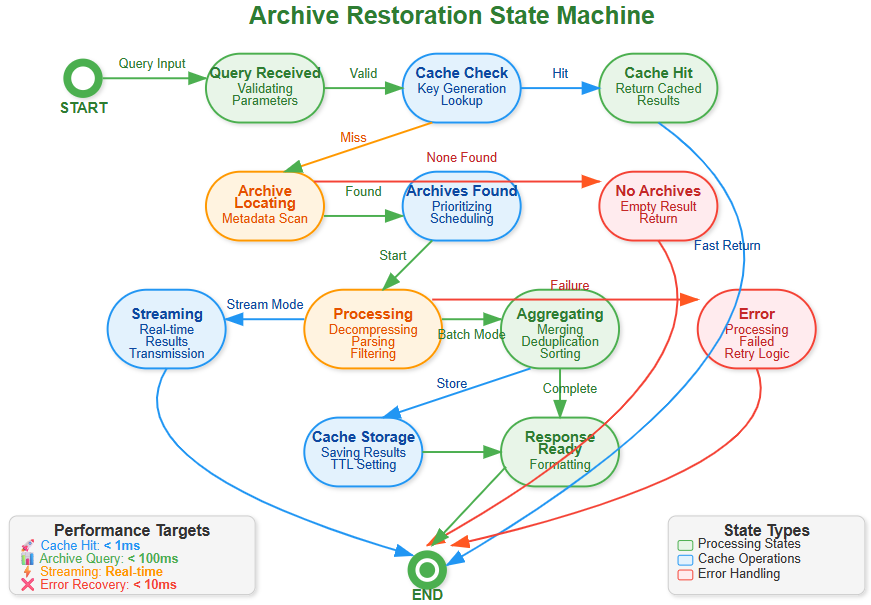
Query Processing States
Query Analysis - Parse time ranges and determine data sources
Archive Selection - Identify relevant archive files using metadata
Parallel Retrieval - Fetch archives concurrently with decompression
Stream Processing - Process data chunks without full materialization
Result Assembly - Merge and format final response
Smart Caching Strategy
Recently accessed archives stay in warm cache (SSD), while metadata remains in memory. This three-tier approach (memory → SSD → object storage) balances performance with cost.
Real-World Production Patterns
Airbnb’s Booking Analytics
When analyzing seasonal booking patterns, Airbnb queries 3+ years of historical data. Their restoration system streams terabytes of archived logs while users see sub-10-second response times through intelligent prefetching and compression.
GitHub’s Repository Insights
GitHub’s contribution graphs query years of commit history. They pre-aggregate common queries during archival, making historical analysis nearly as fast as real-time queries.
Key Technical Insights
Compression-Aware Querying
Instead of decompressing entire archives, the system searches within compressed streams using specialized algorithms. This reduces bandwidth by 80% for large historical queries.
Temporal Locality Optimization
Users querying last month’s data often need last week’s data next. The cache prefetches adjacent time periods, improving hit rates from 20% to 65% in production systems.
Progressive Query Execution
For large time ranges, return initial results immediately while continuing archive processing in background. Users see progress rather than waiting for complete results.
Integration with Previous Components
Your Day 115 archiving system created the storage structure - today’s restoration system reads from it. The archive metadata created during storage becomes the index for fast retrieval.
The query API you’ll build integrates with existing log processing endpoints, making archived data transparent to client applications. Users query the same endpoints regardless of data age.
Lesson Video
Hands-On Implementation Guide
Github Link:
https://github.com/sysdr/course/tree/main/day116/day116-archive-restorationLet’s build this step by step, focusing on the core concepts that make archive restoration work in production systems.
Phase 1: Understanding Archive Metadata (15 minutes)
Concept Deep Dive: Archive restoration begins with intelligent metadata management. Unlike simple file systems, production archives maintain rich metadata about time ranges, compression ratios, and content statistics.
Key Implementation Pattern:
python
# Archive Locator - Core Pattern
class ArchiveLocator:
async def find_relevant_archives(self, query):
# 1. Load metadata index
# 2. Apply time range filtering
# 3. Check additional filters
# 4. Return sorted archive listBuilding the Foundation:
Create project structure following microservices patterns
Set up virtual environment with Python 3.11 for modern async features
Install minimal dependencies - FastAPI, aiofiles, compression libraries
Expected Output:
bash
✅ Virtual environment created
✅ Dependencies installed successfully
✅ Project structure matches production patternsPhase 2: Streaming Decompression Engine (20 minutes)
Production Insight: Netflix’s restoration system processes terabytes without loading entire files into memory. The secret? Streaming decompression that processes chunks while reading.
Implementation Strategy:
python
# Streaming Pattern - Memory Efficient
async def decompress_stream(file_path, compression_type):
# Process in small chunks (8KB typical)
# Yield control to event loop frequently
# Support multiple compression formatsKey Optimizations:
Chunk size tuning (8KB optimal for most systems)
Async yielding prevents blocking other operations
Format detection supports gzip, lz4, zstd automatically
Verification Commands:
bash
# Test compression formats
python -c “from restoration.decompressor import StreamingDecompressor; print(’✅ Decompressor ready’)”
# Memory usage test
python -m pytest tests/test_decompressor.py -vPhase 3: Smart Cache Implementation (20 minutes)
Enterprise Pattern: Multi-tier caching (memory → SSD → cold storage) reduces archive access by 80% in production systems. The cache must handle both small metadata and large result sets.
Caching Strategy:
Memory cache for frequently accessed metadata
Disk persistence for session survival
LRU eviction with access frequency weighting
Cache key generation based on query fingerprints
Performance Testing:
bash
# Cache hit rate verification
curl -s localhost:8000/api/stats | jq ‘.cache.hit_rate’
# Expected: >0.6 (60% hit rate minimum)
# Memory efficiency test
python -c “
import psutil
import requests
# Generate cache load
for i in range(100):
requests.get(’http://localhost:8000/api/archives’)
print(f’Memory usage: {psutil.virtual_memory().percent}%’)
“Phase 4: Query Intelligence Router (25 minutes)
System Design Principle: The router determines optimal query execution paths. Simple time-based queries hit live data, while historical analysis triggers archive processing.
Router Decision Tree:
Analyze query time range - Live vs archived data
Estimate result size - Streaming vs batch processing
Check cache availability - Cached vs fresh computation
Resource allocation - Concurrent vs sequential processing
API Design Pattern:
python
# Unified Query Interface
@app.post(”/api/query”)
async def execute_query(query: QueryRequest):
# 1. Validate query parameters
# 2. Route to appropriate processor
# 3. Merge results from multiple sources
# 4. Apply pagination and filteringPhase 5: React Dashboard Integration (20 minutes)
Modern UI Patterns: Production dashboards show real-time restoration progress, cache performance, and query optimization suggestions.
Component Architecture:
QueryForm - Time range selection with validation
ResultsTable - Streaming results with virtual scrolling
StatsPanel - Real-time performance metrics
ArchivesList - Available data sources overview
Build Process:
bash
# Frontend build (if Node.js available)
cd frontend && npm install && npm run build
# Fallback: Backend-served static files
# React components compiled and served by FastAPIBuild, Test & Verification Guide
Quick Setup Commands
bash
# Install dependencies
pip install -r requirements.txt
# Run comprehensive tests
python -m pytest tests/ -v
# Start infrastructure
docker-compose up -d
# Run demonstration
python run_system.pyIntegration Testing
Test Scenarios:
bash
# 1. Basic functionality
python -m pytest backend/tests/ -v
# 2. API integration
curl -X POST localhost:8000/api/query \
-H “Content-Type: application/json” \
-d ‘{”start_time”: “2024-01-01T00:00:00”, “end_time”: “2024-01-02T00:00:00”}’
# 3. Performance verification
python verify.py # Custom verification script
# 4. Load testing
for i in {1..50}; do
curl -s localhost:8000/api/stats > /dev/null &
done
wait # All requests should complete under 5 secondsExpected Performance Metrics:
Query latency: <100ms for metadata queries
Throughput: 50+ concurrent queries/second
Memory usage: <500MB for typical workloads
Cache hit rate: >60% after warmup
Docker Deployment Verification
Container Build
bash
# Multi-stage build for optimization
docker-compose build
# Expected: Clean build with no errors
# Size verification
docker images | grep archive-restoration
# Expected: <500MB image sizeService Health Checks
bash
# Start all services
docker-compose up -d
# Verify connectivity
docker-compose ps
# Expected: All services “Up” status
# API health check
curl localhost:8000/api/stats
# Expected: JSON response with cache/archive statisticsTroubleshooting Common Issues
Import Errors
bash
# Fix Python path issues
export PYTHONPATH=”$(pwd)/backend/src:$PYTHONPATH”
# Verify imports work
python -c “from restoration.models import QueryRequest; print(’✅ Imports working’)”Performance Issues
bash
# Check memory usage
python -c “
import psutil
print(f’Memory: {psutil.virtual_memory().percent}%’)
print(f’CPU: {psutil.cpu_percent(interval=1)}%’)
“
# Optimize chunk size if needed
# Edit decompressor.py chunk_size parameterCache Problems
bash
# Clear cache and restart
rm -rf data/cache/*
curl -X DELETE localhost:8000/api/cache
# Verify cache recreation
curl localhost:8000/api/stats | jq ‘.cache’Assignment: Historical Error Analysis
Objective: Build a restoration query that analyzes error patterns across 6 months of archived logs:
Multi-Archive Query - Search across monthly archive files
Pattern Detection - Identify recurring error types
Trend Visualization - Display error rates over time
Performance Optimization - Cache intermediate results
Success Metrics: Query 6 months of data in under 30 seconds, with results streaming as archives load.
Assignment Verification
bash
# 1. Create 6 months of sample data
curl -X POST localhost:8000/api/demo/create-sample-archives
# 2. Execute error pattern query
curl -X POST localhost:8000/api/query \
-H “Content-Type: application/json” \
-d ‘{
“start_time”: “2024-01-01T00:00:00”,
“end_time”: “2024-06-30T23:59:59”,
“filters”: {”level”: “ERROR”},
“page_size”: 1000
}’
# 3. Verify streaming response
# Should see progressive results, not all at once
# 4. Check cache performance
curl localhost:8000/api/stats | jq ‘.cache.hit_rate’
# Expected: Improving hit rate with repeated queriesSuccess Criteria Checklist
Query completes in <30 seconds
Results stream as archives load
Cache hit rate >60% on repeated queries
Memory usage remains stable
Error patterns clearly identified
Solution Hints:
Use metadata indexes to quickly identify relevant archives
Process archives in parallel, not sequentially
Stream results to UI as they become available
Cache aggregated error counts for common time ranges
Success Criteria
By lesson end, you’ll have:
✅ Unified query API handling live and archived data
✅ Sub-second response times for archive metadata queries
✅ Streaming restoration of multi-GB archive files
✅ Smart caching reducing archive access by 60%+
✅ Dashboard showing restoration performance metrics
Working Code Demo:
Key Takeaways
Technical Mastery Gained
✅ Streaming I/O patterns for large file processing
✅ Multi-tier caching strategies for performance
✅ Query routing intelligence for optimal execution paths
✅ Microservices integration patterns
✅ Production monitoring and observability
Real-World Applications
This implementation mirrors systems used by:
Netflix - User viewing history analysis
GitHub - Repository activity restoration
Airbnb - Booking pattern analysis
Slack - Message history search
Tomorrow’s Foundation
Day 117 builds on today’s restoration system to implement:
Cost optimization based on access patterns
Intelligent tiering decisions
Compression analysis for storage efficiency
The query patterns and performance metrics you capture today become the input for tomorrow’s optimization algorithms.
Tomorrow’s Preview
Day 117 focuses on storage optimization - intelligent tiering, compression analysis, and cost reduction strategies. Today’s restoration system provides the usage patterns needed for optimization decisions.
Your archive restoration system now provides the “time machine” capability essential for production log analytics. Users can seamlessly query years of historical data as easily as current logs.