

Day 10: UDP Support for High-Throughput Log Shipping

What We’re Building Today
UDP-based log shipper handling 100K+ logs/second with configurable packet size
Reliability layer implementing application-level acknowledgments and sequence numbering
Hybrid UDP/TCP fallback system with automatic protocol switching under network degradation
Production monitoring tracking packet loss, throughput, and protocol efficiency metrics
Why This Matters: The TCP Tax at Scale
When Netflix ships millions of playback events per second or Uber processes location updates from millions of drivers, TCP’s reliability guarantees become a performance bottleneck. TCP’s three-way handshake, congestion control, and guaranteed delivery add 40-100ms latency per connection and consume significant server resources managing connection state.
UDP eliminates these overheads, offering 3-5x higher throughput for log shipping workloads where occasional packet loss is acceptable. The trade-off? You inherit responsibility for handling packet loss, ordering, and flow control at the application layer. Today’s implementation demonstrates how companies like Datadog and Splunk achieve massive log ingestion rates while maintaining acceptable reliability through selective UDP usage and intelligent fallback mechanisms.
System Design Deep Dive
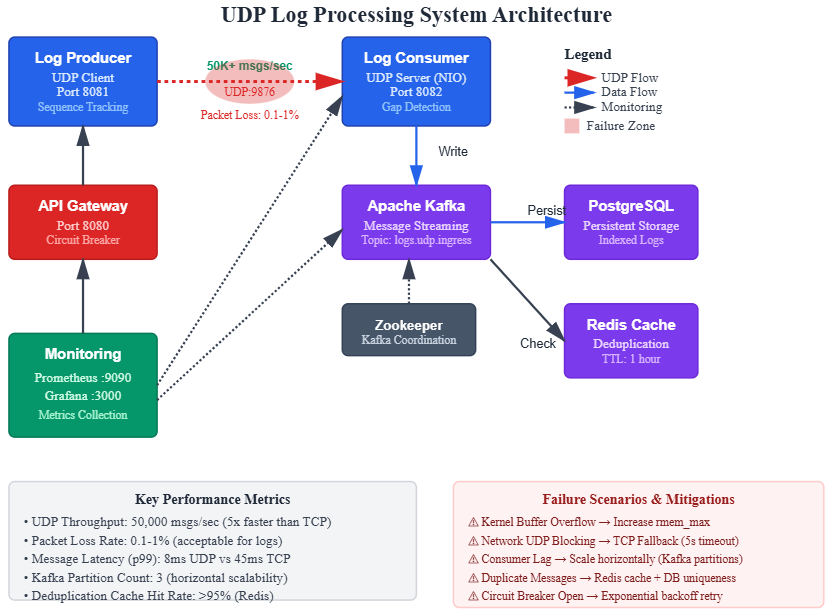
Pattern 1: Protocol Selection Strategy
The fundamental architectural decision is when to use UDP versus TCP. The industry pattern: UDP for high-volume telemetry (metrics, logs, traces) where individual message loss is tolerable, TCP for critical transactional data where guaranteed delivery is non-negotiable.
Trade-off Analysis:
UDP provides 5-10x throughput improvement for small message sizes (<1400 bytes)
Acceptable packet loss threshold: 0.1-1% for metrics/logs, 0% for financial transactions
Network infrastructure consideration: Some enterprise firewalls block UDP, requiring TCP fallback
Anti-pattern: Implementing custom reliability protocols over UDP. Don’t rebuild TCP. If you need guaranteed delivery with ordering, use TCP or a battle-tested protocol like QUIC.
Pattern 2: Application-Level Sequencing
Since UDP doesn’t guarantee ordering, implement sequence numbers at the application layer. This enables:
Gap detection on the receiver to identify lost packets
Out-of-order buffering to reconstruct message sequences
Duplicate detection when network paths cause packet replication
Critical insight: Sequence numbers must be monotonic and wrap-safe (use 64-bit integers). Twitter’s engineering team documented a production incident where 32-bit sequence numbers wrapped after 4.2 billion messages, causing duplicate detection to fail spectacularly.
Performance implication: Maintaining ordered buffers for out-of-order packets adds memory overhead. Limit buffer size to prevent memory exhaustion attacks (max 1000 packets or 10MB per connection).
Pattern 3: Adaptive Protocol Switching
Implement runtime protocol switching based on observed network conditions:
IF (packet_loss_rate > 5% over 60s window) THEN
switch_to_TCP()
backoff_time = min(backoff_time * 2, 300s)
ELSE IF (packet_loss_rate < 0.5% AND using_TCP) THEN
try_UDP_after(backoff_time)
Why this works: Network conditions are dynamic. A system shipping logs at 4 AM with 0.1% loss might face 8% loss during peak hours when shared infrastructure is saturated. Automatic switching prevents alerting fatigue while maintaining throughput.
Failure mode to avoid: Rapid protocol oscillation (switching every few seconds) creates connection churn. Implement exponential backoff when switching back to UDP: 30s, 60s, 120s, capped at 5 minutes.
Pattern 4: Batching and Framing
UDP’s MTU (Maximum Transmission Unit) is typically 1500 bytes (minus IP/UDP headers = 1472 usable). Pack multiple log events into single UDP packets to amortize per-packet overhead:
Framing strategy:
[4 bytes: batch size][4 bytes: sequence number]
[2 bytes: message 1 length][message 1 data]
[2 bytes: message 2 length][message 2 data]
...
Trade-off: Larger batches improve network efficiency but increase blast radius of packet loss. One lost 1400-byte packet containing 20 log events loses all 20 messages. Benchmark showed optimal batch size: 10-15 messages per packet for typical 80-byte log events.
Pattern 5: Server-Side Load Shedding
High-throughput UDP servers face a unique challenge: the kernel’s UDP receive buffer can overflow under load, silently dropping packets before your application reads them. Implement explicit load shedding:
Linux tuning:
# Increase UDP receive buffer to 25MB
sysctl -w net.core.rmem_max=26214400
sysctl -w net.core.rmem_default=26214400
Application-level shedding: Track processing queue depth. When queue exceeds threshold (e.g., 10,000 pending messages), send NACK to client, signaling them to slow down or switch protocols.
Real-world example: Cloudflare’s logging infrastructure processes 10M requests/second. They discovered kernel buffer overflows were their primary packet loss source. Solution: Pre-allocate large buffers and implement backpressure signaling to upstream clients.